DNS 优化¶
前面我们讲解了在 Kubernetes 中我们可以使用 CoreDNS 来进行集群的域名解析,但是如果在集群规模较大并发较高的情况下我们仍然需要对 DNS 进行优化,典型的就是大家比较熟悉的 CoreDNS 会出现超时5s的情况。
超时原因¶
在 iptables 模式下(默认情况下),每个服务的 kube-proxy 在主机网络名称空间的 nat 表中创建一些 iptables 规则。 比如在集群中具有两个 DNS 服务器实例的 kube-dns 服务,其相关规则大致如下所示:
(1) -A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES
<...>
(2) -A KUBE-SERVICES -d 10.96.0.10/32 -p udp -m comment --comment "kube-system/kube-dns:dns cluster IP" -m udp --dport 53 -j KUBE-SVC-TCOU7JCQXEZGVUNU
<...>
(3) -A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-LLLB6FGXBLX6PZF7
(4) -A KUBE-SVC-TCOU7JCQXEZGVUNU -m comment --comment "kube-system/kube-dns:dns" -j KUBE-SEP-LRVEW52VMYCOUSMZ
<...>
(5) -A KUBE-SEP-LLLB6FGXBLX6PZF7 -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 10.32.0.6:53
<...>
(6) -A KUBE-SEP-LRVEW52VMYCOUSMZ -p udp -m comment --comment "kube-system/kube-dns:dns" -m udp -j DNAT --to-destination 10.32.0.7:53
我们知道每个 Pod 的 /etc/resolv.conf 文件中都有填充的 nameserver 10.96.0.10 这个条目。所以来自 Pod 的 DNS 查找请求将发送到 10.96.0.10,这是 kube-dns 服务的 ClusterIP 地址。 由于 (1) 请求进入 KUBE-SERVICE 链,然后匹配规则 (2),最后根据 (3) 的 random 随机模式,跳转到 (5) 或 (6) 条目,将请求 UDP 数据包的目标 IP 地址修改为 DNS 服务器的实际 IP 地址,这是通过 DNAT 完成的。其中 10.32.0.6 和 10.32.0.7 是我们集群中 CoreDNS 的两个 Pod 副本的 IP 地址。
内核中的 DNAT¶
DNAT 的主要职责是同时更改传出数据包的目的地,响应数据包的源,并确保对所有后续数据包进行相同的修改。后者严重依赖于连接跟踪机制,也称为 conntrack,它被实现为内核模块。conntrack 会跟踪系统中正在进行的网络连接。
conntrack 中的每个连接都由两个元组表示,一个元组用于原始请求(IP_CT_DIR_ORIGINAL),另一个元组用于答复(IP_CT_DIR_REPLY)。对于 UDP,每个元组都由源 IP 地址,源端口以及目标 IP 地址和目标端口组成,答复元组包含存储在src 字段中的目标的真实地址。
例如,如果 IP 地址为 10.40.0.17 的 Pod 向 kube-dns 的 ClusterIP 发送一个请求,该请求被转换为 10.32.0.6,则将创建以下元组:
原始:src = 10.40.0.17 dst = 10.96.0.10 sport = 53378 dport = 53
回复:src = 10.32.0.6 dst = 10.40.0.17 sport = 53 dport = 53378
通过这些条目内核可以相应地修改任何相关数据包的目的地和源地址,而无需再次遍历 DNAT 规则,此外,它将知道如何修改回复以及应将回复发送给谁。创建 conntrack 条目后,将首先对其进行确认,然后如果没有已确认的 conntrack 条目具有相同的原始元组或回复元组,则内核将尝试确认该条目。conntrack 创建和 DNAT 的简化流程如下所示:

问题¶
DNS 客户端 (glibc 或 musl libc) 会并发请求 A 和 AAAA 记录,跟 DNS Server 通信自然会先 connect (建立fd),后面请求报文使用这个 fd 来发送,由于 UDP 是无状态协议,connect 时并不会创建 conntrack 表项, 而并发请求的 A 和 AAAA 记录默认使用同一个 fd 发包,这时它们源 Port 相同,当并发发包时,两个包都还没有被插入 conntrack 表项,所以 netfilter 会为它们分别创建 conntrack 表项,而集群内请求 CoreDNS 都是访问的 CLUSTER-IP,报文最终会被 DNAT 成一个具体的 Pod IP,当两个包被 DNAT 成同一个 IP,最终它们的五元组就相同了,在最终插入的时候后面那个包就会被丢掉,如果 DNS 的 Pod 副本只有一个实例的情况就很容易发生,现象就是 DNS 请求超时,客户端默认策略是等待 5s 自动重试,如果重试成功,我们看到的现象就是 DNS 请求有 5s 的延时。
具体原因可以参考 weave works 总结的文章 Racy conntrack and DNS lookup timeouts。
- 只有多个线程或进程,并发从同一个 socket 发送相同五元组的 UDP 报文时,才有一定概率会发生
- glibc、musl(alpine linux 的 libc 库)都使用
parallel query, 就是并发发出多个查询请求,因此很容易碰到这样的冲突,造成查询请求被丢弃 - 由于 ipvs 也使用了 conntrack, 使用 kube-proxy 的 ipvs 模式,并不能避免这个问题
解决方法¶
要彻底解决这个问题最好当然是内核上去 FIX 掉这个 BUG,除了这种方法之外我们还可以使用其他方法来进行规避,我们可以避免相同五元组 DNS请求的并发。
在 resolv.conf 中就有两个相关的参数可以进行配置:
single-request-reopen:发送 A 类型请求和 AAAA 类型请求使用不同的源端口,这样两个请求在 conntrack 表中不占用同一个表项,从而避免冲突。single-request:避免并发,改为串行发送 A 类型和 AAAA 类型请求。没有了并发,从而也避免了冲突。
要给容器的 resolv.conf 加上 options 参数,有几个办法:
-
- 在容器的
ENTRYPOINT或者CMD脚本中,执行/bin/echo 'options single-request-reopen' >> /etc/resolv.conf
- 在容器的
-
- 在 Pod 的 postStart hook 中添加:
lifecycle: postStart: exec: command: - /bin/sh - -c - "/bin/echo 'options single-request-reopen' >> /etc/resolv.conf"
- 在 Pod 的 postStart hook 中添加:
-
- 使用
template.spec.dnsConfig配置:template: spec: dnsConfig: options: - name: single-request-reopen
- 使用
-
- 使用 ConfigMap 覆盖 Pod 里面的
/etc/resolv.conf:# configmap apiVersion: v1 data: resolv.conf: | nameserver 1.2.3.4 search default.svc.cluster.local svc.cluster.local cluster.local options ndots:5 single-request-reopen timeout:1 kind: ConfigMap metadata: name: resolvconf --- # Pod Spec spec: volumeMounts: - name: resolv-conf mountPath: /etc/resolv.conf subPath: resolv.conf # 在某个目录下面挂载一个文件(保证不覆盖当前目录)需要使用subPath -> 不支持热更新 ... volumes: - name: resolv-conf configMap: name: resolvconf items: - key: resolv.conf path: resolv.conf
- 使用 ConfigMap 覆盖 Pod 里面的
上面的方法在一定程度上可以解决 DNS 超时的问题,但更好的方式是使用本地 DNS 缓存,容器的 DNS 请求都发往本地的 DNS 缓存服务,也就不需要走 DNAT,当然也不会发生 conntrack 冲突了,而且还可以有效提升 CoreDNS 的性能瓶颈。
性能测试¶
这里我们使用一个简单的 golang 程序来测试下使用本地 DNS 缓存的前后性能。代码如下所示:
// main.go
package main
import (
"context"
"flag"
"fmt"
"net"
"sync/atomic"
"time"
)
var host string
var connections int
var duration int64
var limit int64
var timeoutCount int64
func main() {
flag.StringVar(&host, "host", "", "Resolve host")
flag.IntVar(&connections, "c", 100, "Connections")
flag.Int64Var(&duration, "d", 0, "Duration(s)")
flag.Int64Var(&limit, "l", 0, "Limit(ms)")
flag.Parse()
var count int64 = 0
var errCount int64 = 0
pool := make(chan interface{}, connections)
exit := make(chan bool)
var (
min int64 = 0
max int64 = 0
sum int64 = 0
)
go func() {
time.Sleep(time.Second * time.Duration(duration))
exit <- true
}()
endD:
for {
select {
case pool <- nil:
go func() {
defer func() {
<-pool
}()
resolver := &net.Resolver{}
now := time.Now()
_, err := resolver.LookupIPAddr(context.Background(), host)
use := time.Since(now).Nanoseconds() / int64(time.Millisecond)
if min == 0 || use < min {
min = use
}
if use > max {
max = use
}
sum += use
if limit > 0 && use >= limit {
timeoutCount++
}
atomic.AddInt64(&count, 1)
if err != nil {
fmt.Println(err.Error())
atomic.AddInt64(&errCount, 1)
}
}()
case <-exit:
break endD
}
}
fmt.Printf("request count:%d\nerror count:%d\n", count, errCount)
fmt.Printf("request time:min(%dms) max(%dms) avg(%dms) timeout(%dn)\n", min, max, sum/count, timeoutCount)
}
首先配置好 golang 环境,然后直接构建上面的测试应用:
$ go build -o testdns .
构建完成后生成一个 testdns 的二进制文件,然后我们将这个二进制文件拷贝到任意一个 Pod 中去进行测试:
$ kubectl cp testdns svc-demo-546b7bcdcf-6xsnr:/root -n default
拷贝完成后进入这个测试的 Pod 中去:
$ kubectl exec -it svc-demo-546b7bcdcf-6xsnr -- /bin/bash
root@svc-demo-546b7bcdcf-6xsnr:/# cd /root
然后我们执行 testdns 程序来进行压力测试,比如执行 200 个并发,持续 30 秒:
# 对 nginx-service.default 这个地址进行解析
root@svc-demo-546b7bcdcf-6xsnr:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
lookup nginx-service.default on 10.96.0.10:53: no such host
lookup nginx-service.default on 10.96.0.10:53: no such host
lookup nginx-service.default on 10.96.0.10:53: no such host
lookup nginx-service.default on 10.96.0.10:53: no such host
lookup nginx-service.default on 10.96.0.10:53: no such host
request count:12533
error count:5
request time:min(5ms) max(16871ms) avg(425ms) timeout(475n)
root@svc-demo-546b7bcdcf-6xsnr:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
lookup nginx-service.default on 10.96.0.10:53: no such host
lookup nginx-service.default on 10.96.0.10:53: no such host
lookup nginx-service.default on 10.96.0.10:53: no such host
request count:10058
error count:3
request time:min(4ms) max(12347ms) avg(540ms) timeout(487n)
root@svc-demo-546b7bcdcf-6xsnr:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
lookup nginx-service.default on 10.96.0.10:53: no such host
lookup nginx-service.default on 10.96.0.10:53: no such host
request count:12242
error count:2
request time:min(3ms) max(12206ms) avg(478ms) timeout(644n)
root@svc-demo-546b7bcdcf-6xsnr:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:11008
error count:0
request time:min(3ms) max(11110ms) avg(496ms) timeout(478n)
root@svc-demo-546b7bcdcf-6xsnr:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:9141
error count:0
request time:min(4ms) max(11198ms) avg(607ms) timeout(332n)
root@svc-demo-546b7bcdcf-6xsnr:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:9126
error count:0
request time:min(4ms) max(11554ms) avg(613ms) timeout(197n)
我们可以看到大部分平均耗时都是在 500ms 左右,这个性能是非常差的,而且还有部分解析失败的条目。接下来我们就来尝试使用 NodeLocal DNSCache 来提升 DNS 的性能和可靠性。
NodeLocal DNSCache¶
NodeLocal DNSCache 通过在集群节点上运行一个 DaemonSet 来提高集群 DNS 性能和可靠性。处于 ClusterFirst 的 DNS 模式下的 Pod 可以连接到 kube-dns 的 serviceIP 进行 DNS 查询,通过 kube-proxy 组件添加的 iptables 规则将其转换为 CoreDNS 端点。通过在每个集群节点上运行 DNS 缓存,NodeLocal DNSCache 可以缩短 DNS 查找的延迟时间、使 DNS 查找时间更加一致,以及减少发送到 kube-dns 的 DNS 查询次数。
在集群中运行 NodeLocal DNSCache 有如下几个好处:
- 如果本地没有 CoreDNS 实例,则具有最高 DNS QPS 的 Pod 可能必须到另一个节点进行解析,使用
NodeLocal DNSCache后,拥有本地缓存将有助于改善延迟 - 跳过 iptables DNAT 和连接跟踪将有助于减少 conntrack 竞争并避免 UDP DNS 条目填满 conntrack 表(上面提到的5s超时问题就是这个原因造成的)
- 从本地缓存代理到 kube-dns 服务的连接可以升级到 TCP,TCP conntrack 条目将在连接关闭时被删除,而 UDP 条目必须超时(默认
nfconntrackudp_timeout是 30 秒) - 将 DNS 查询从 UDP 升级到 TCP 将减少归因于丢弃的 UDP 数据包和 DNS 超时的尾部等待时间,通常长达 30 秒(3 次重试+ 10 秒超时)
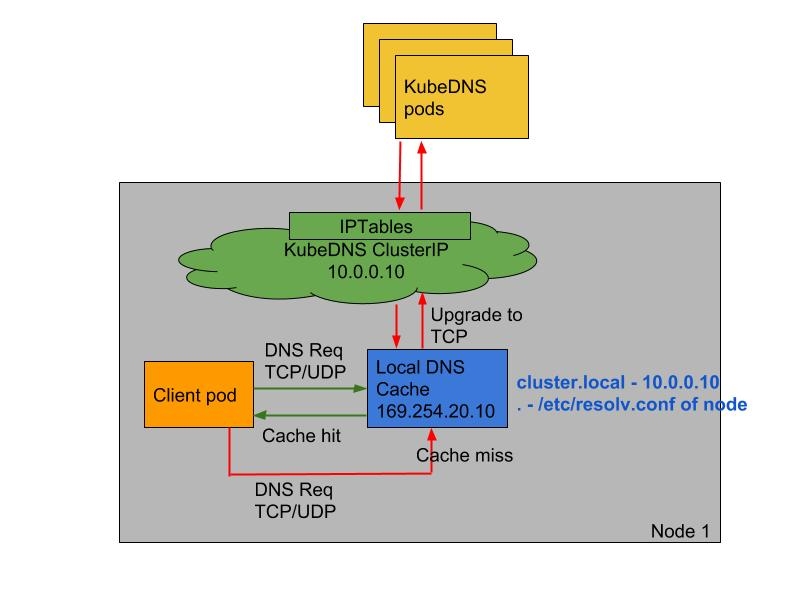
要安装 NodeLocal DNSCache 也非常简单,直接获取官方的资源清单即可:
$ wget https://github.com/kubernetes/kubernetes/raw/master/cluster/addons/dns/nodelocaldns/nodelocaldns.yaml
该资源清单文件中包含几个变量值得注意,其中:
__PILLAR__DNS__SERVER__:表示 kube-dns 这个 Service 的 ClusterIP,可以通过命令kubectl get svc -n kube-system | grep kube-dns | awk'{ print $3 }'获取(我们这里就是10.96.0.10)__PILLAR__LOCAL__DNS__:表示 DNSCache 本地的 IP,默认为169.254.20.10__PILLAR__DNS__DOMAIN__:表示集群域,默认就是cluster.local
另外还有两个参数 __PILLAR__CLUSTER__DNS__ 和 __PILLAR__UPSTREAM__SERVERS__,这两个参数会通过镜像 1.15.16 版本去进行自动配置,对应的值来源于 kube-dns 的 ConfigMap 和定制的 Upstream Server 配置。直接执行如下所示的命令即可安装:
$ sed 's/k8s.gcr.io\/dns/cnych/g
s/__PILLAR__DNS__SERVER__/10.96.0.10/g
s/__PILLAR__LOCAL__DNS__/169.254.20.10/g
s/__PILLAR__DNS__DOMAIN__/cluster.local/g' nodelocaldns.yaml |
kubectl apply -f -
可以通过如下命令来查看对应的 Pod 是否已经启动成功:
$ kubectl get pods -n kube-system -l k8s-app=node-local-dns
NAME READY STATUS RESTARTS AGE
node-local-dns-4wclp 1/1 Running 0 5m43s
node-local-dns-gxq57 1/1 Running 0 5m43s
node-local-dns-v7gtz 1/1 Running 0 5m43s
需要注意的是这里使用 DaemonSet 部署 node-local-dns 使用了 hostNetwork=true,会占用宿主机的 8080 端口,所以需要保证该端口未被占用。
但是到这里还没有完,如果 kube-proxy 组件使用的是 ipvs 模式的话我们还需要修改 kubelet 的 --cluster-dns 参数,将其指向 169.254.20.10,Daemonset 会在每个节点创建一个网卡来绑这个 IP,Pod 向本节点这个 IP 发 DNS 请求,缓存没有命中的时候才会再代理到上游集群 DNS 进行查询。iptables 模式下 Pod 还是向原来的集群 DNS 请求,节点上有这个 IP 监听,会被本机拦截,再请求集群上游 DNS,所以不需要更改 --cluster-dns 参数。
如果担心线上环境修改
--cluster-dns参数会产生影响,我们也可以直接在新部署的 Pod 中通过 dnsConfig 配置使用新的 localdns 的地址来进行解析。
由于我这里使用的是 kubeadm 安装的 1.19 版本的集群,所以我们只需要替换节点上 /var/lib/kubelet/config.yaml 文件中的 clusterDNS 这个参数值,然后重启即可:
$ sed -i 's/10.96.0.10/169.254.20.10/g' /var/lib/kubelet/config.yaml
$ systemctl daemon-reload && systemctl restart kubelet
待 node-local-dns 安装配置完成后,我们可以部署一个新的 Pod 来验证下:
# test-node-local-dns.yaml
apiVersion: v1
kind: Pod
metadata:
name: test-node-local-dns
spec:
containers:
- name: local-dns
image: busybox
command: ["/bin/sh", "-c", "sleep 60m"]
直接部署:
$ kubectl apply -f test-node-local-dns.yaml
$ kubectl exec -it test-node-local-dns /bin/sh
/ # cat /etc/resolv.conf
nameserver 169.254.20.10
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
我们可以看到 nameserver 已经变成 169.254.20.10 了,当然对于之前的历史 Pod 要想使用 node-local-dns 则需要重建。
接下来我们重建前面压力测试 DNS 的 Pod,重新将 testdns 二进制文件拷贝到 Pod 中去:
# 拷贝到重建的 Pod 中
$ kubectl cp testdns svc-demo-546b7bcdcf-b5mkt:/root
$ kubectl exec -it svc-demo-546b7bcdcf-b5mkt -- /bin/bash
root@svc-demo-546b7bcdcf-b5mkt:/# cat /etc/resolv.conf
nameserver 169.254.20.10 # 可以看到 nameserver 已经更改
search default.svc.cluster.local svc.cluster.local cluster.local
options ndots:5
root@svc-demo-546b7bcdcf-b5mkt:/# cd /root
root@svc-demo-546b7bcdcf-b5mkt:~# ls
testdns
# 重新执行压力测试
root@svc-demo-546b7bcdcf-b5mkt:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:16297
error count:0
request time:min(2ms) max(5270ms) avg(357ms) timeout(8n)
root@svc-demo-546b7bcdcf-b5mkt:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:15982
error count:0
request time:min(2ms) max(5360ms) avg(373ms) timeout(54n)
root@svc-demo-546b7bcdcf-b5mkt:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:25631
error count:0
request time:min(3ms) max(958ms) avg(232ms) timeout(0n)
root@svc-demo-546b7bcdcf-b5mkt:~# ./testdns -host nginx-service.default -c 200 -d 30 -l 5000
request count:23388
error count:0
request time:min(6ms) max(1130ms) avg(253ms) timeout(0n)
从上面的结果可以看到无论是最大解析时间还是平均解析时间都比之前默认的 CoreDNS 提示了不少的效率,所以我们还是非常推荐在线上环境部署 NodeLocal DNSCache 来提升 DNS 的性能和可靠性的,唯一的缺点就是由于 LocalDNS 使用的是 DaemonSet 模式部署,所以如果需要更新镜像则可能会中断服务(不过可以使用一些第三方的增强组件来实现原地升级解决这个问题,比如 openkruise)。