Kubernetes 零宕机滚动更新
软件世界的发展比以往任何时候都快,为了保持竞争力需要尽快推出新的软件版本,而又不影响在线得用户。许多企业已将工作负载迁移到了 Kubernetes 集群,Kubernetes 集群本身就考虑到了一些生产环境的实践,但是要让 Kubernetes 实现真正的零停机不中断或丢失请求,我们还需要做一些额外的操作才行。
软件世界的发展比以往任何时候都快,为了保持竞争力需要尽快推出新的软件版本,而又不影响在线得用户。许多企业已将工作负载迁移到了 Kubernetes 集群,Kubernetes 集群本身就考虑到了一些生产环境的实践,但是要让 Kubernetes 实现真正的零停机不中断或丢失请求,我们还需要做一些额外的操作才行。
近来由于武汉冠状病毒疫情的扩散,很多公司不得不开始了远程办公的模式,远程办公最大的成本自然是沟通成本了,对于我们开发人员来说最重要的自然也是有一个顺手的 IDE 工具,现在在云端作业的工具也在逐渐增长,比如最近比较流行的设计应用 Figma,就完全是云端操作的方式,大有要取代 Sketch 的趋势,对于开发工具来说云端 IDE 也逐渐受到大家重视,特别是对于远程办公的团队,Cloud IDE 允许开发团队在一个统一的开发环境中实时协作的工具,这可以大大提高生产效率。而且只需要通过 web 浏览器就可以访问,还有一个优点就是可以利用集群的能力,这可以大大超过我们之前的个人 PC 的处理能力,我们也不用为本地 IDE 占用了电脑大量资源而苦恼了。
code-server 就是一个可以运行在服务器上面直接通过浏览器来访问的 VSCode,VSCode 是一个现代化的代码编辑器,支持 Git、代码调试器、智能代码提示以及各种定制和扩展功能。接下来我们来介绍下如何在我们的 Kubernetes 集群上运行一个 VSCode。
Traefik 2.X 版本发布以来受到了很大的关注,特别是提供的中间件机制非常受欢迎,但是目前对于用户来说能使用的也只有官方提供的中间件,这对于某些特殊场景可能就满足不了需求了,自然而然就想到了自定义中间件,然而现在要想自定义中间件不是一件容易的事情,虽然实现一个中间件很简单,因为目前官方没有提供方法可以将我们自定义的中间件配置到 Traefik 中,所以只能采用比较 low 的一种方法,那就是直接更改官方的源代码了,下面我们以一个简单的示例来说明下如何自定义一个 Traefik 中间件。

前面我们介绍了在 ingress-nginx 中 URL Rewrite 的使用,其中重写路径大部分还是和传统的 nginx 方式差不多,如果我们使用的是比较云原生的 Traefik 来作为我们的网关的话,在遇到有 URL Rewrite 需求的时候又改怎么做呢?前面我们用一篇文章 一文搞懂 Traefik2.1 的使用 介绍了 Traefik2.1 的基本的功能,唯独没有提到 URL Rewrite 这一点,在 Traefik2.1 中我们依然可以很方便的用中间件的方式来完成这个功能。
kube-scheduler 是 kubernetes 的核心组件之一,主要负责整个集群资源的调度功能,根据特定的调度算法和策略,将 Pod 调度到最优的工作节点上面去,从而更加合理、更加充分的利用集群的资源,这也是我们选择使用 kubernetes 一个非常重要的理由。如果一门新的技术不能帮助企业节约成本、提供效率,我相信是很难推进的。
Traefik 是一个开源的可以使服务发布变得轻松有趣的边缘路由器。它负责接收你系统的请求,然后使用合适的组件来对这些请求进行处理。
除了众多的功能之外,Traefik 的与众不同之处还在于它会自动发现适合你服务的配置。当 Traefik 在检查你的服务时,会找到服务的相关信息并找到合适的服务来满足对应的请求。
Traefik 兼容所有主流的集群技术,比如 Kubernetes,Docker,Docker Swarm,AWS,Mesos,Marathon,等等;并且可以同时处理多种方式。(甚至可以用于在裸机上运行的比较旧的软件。)
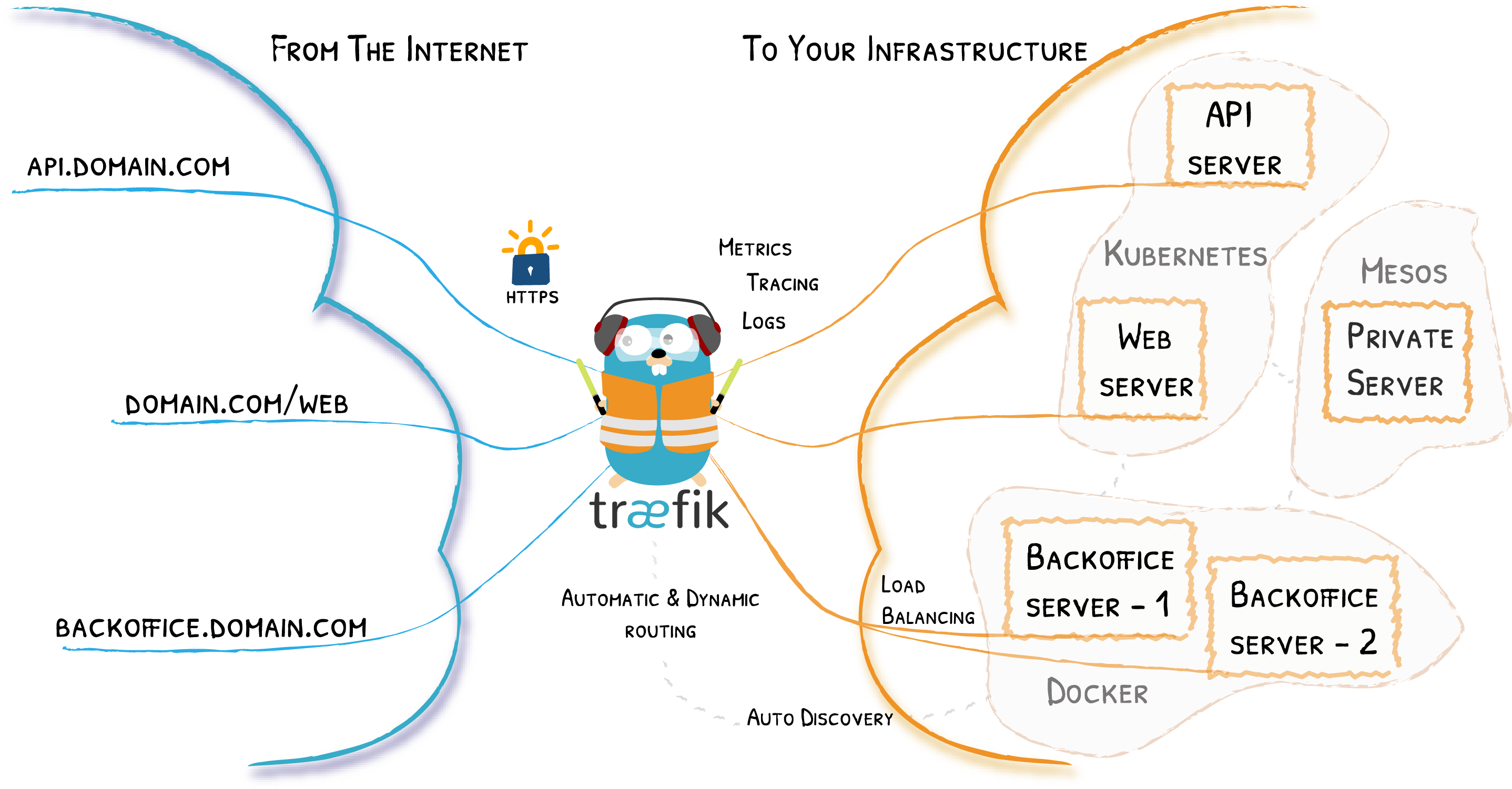
使用 Traefik,不需要维护或者同步一个独立的配置文件:因为一切都会自动配置,实时操作的(无需重新启动,不会中断连接)。使用 Traefik,你可以花更多的时间在系统的开发和新功能上面,而不是在配置和维护工作状态上面花费大量时间。
Prometheus 作为现在最火的云原生监控工具,它的优秀表现是毋庸置疑的。但是在我们使用过程中,随着时间的推移,存储在 Prometheus 中的监控指标数据越来越多,查询的频率也在不断的增加,当我们用 Grafana 添加更多的 Dashboard 的时候,可能慢慢地会体验到 Grafana 已经无法按时渲染图表,并且偶尔还会出现超时的情况,特别是当我们在长时间汇总大量的指标数据的时候,Prometheus 查询超时的情况可能更多了,这时就需要一种能够类似于后台批处理的机制在后台完成这些复杂运算的计算,对于使用者而言只需要查询这些运算结果即可。Prometheus 提供一种记录规则(Recording Rule) 来支持这种后台计算的方式,可以实现对复杂查询的 PromQL 语句的性能优化,提高查询效率。
前面我们主要介绍了 Prometheus 下如何进行白盒监控,我们监控主机的资源用量、容器的运行状态、数据库中间件的运行数据、自动发现 Kubernetes 集群中的资源等等,这些都是支持业务和服务的基础设施,通过白盒能够了解其内部的实际运行状态,通过对监控指标的观察能够预判可能出现的问题,从而对潜在的不确定因素进行优化。而从完整的监控逻辑的角度,除了大量的应用白盒监控以外,还应该添加适当的 Blackbox(黑盒)监控,黑盒监控即以用户的身份测试服务的外部可见性,常见的黑盒监控包括HTTP 探针、TCP 探针 等用于检测站点或者服务的可访问性,以及访问效率等。
黑盒监控相较于白盒监控最大的不同在于黑盒监控是以故障为导向当故障发生时,黑盒监控能快速发现故障,而白盒监控则侧重于主动发现或者预测潜在的问题。一个完善的监控目标是要能够从白盒的角度发现潜在问题,能够在黑盒的角度快速发现已经发生的问题。
Blackbox Exporter 是 Prometheus 社区提供的官方黑盒监控解决方案,其允许用户通过:HTTP、HTTPS、DNS、TCP 以及 ICMP 的方式对网络进行探测。
本文翻译自 A visual guide on troubleshooting Kubernetes deployments。
下面示意图可以帮助你调试 Kubernetes Deployment(你可以在此处【下载它的 PDF 版本】),另外在微信群里面也看到有朋友分享了一个对应的中文版(你可以在此处【下载它的中文版本】):
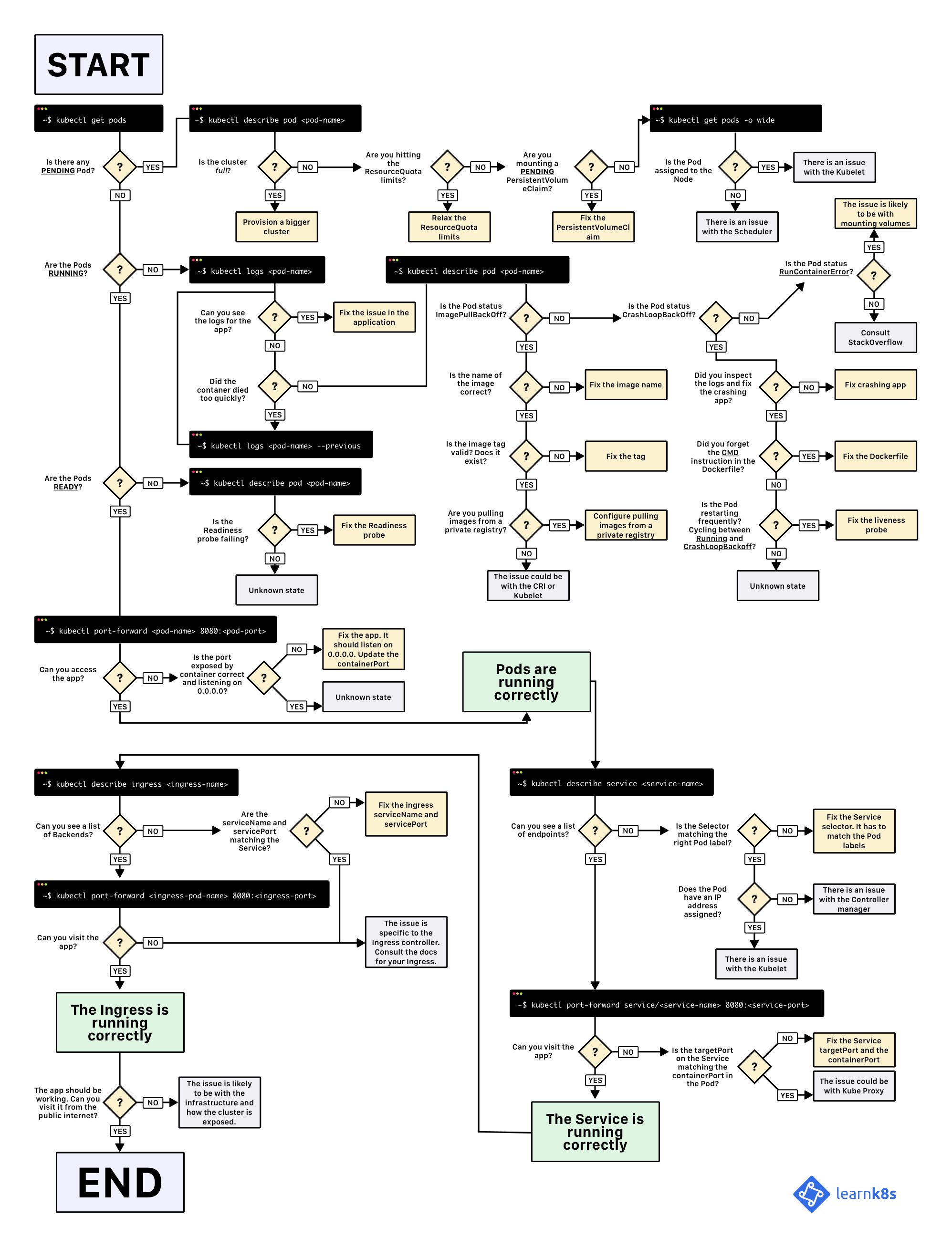
当你希望在 Kubernetes 中部署应用程序时,你通常会定义三个组件:
下面的示意图可以来简单说明:
由于 nginx 的优秀性能表现,所以很多企业在 Kubernetes 中选择 Ingress Controller 的时候依然会选择基于 nginx 的 ingress-nginx,前面文章中我们更多的是介绍更加云原生配置更加灵活的 Traefik,特别是 Traefik 2.0 版本新增中间件概念以后,在配置上就更加方便了,各种需求都可以通过中间件来实现,对于 ingress-nginx 来说配置就稍微麻烦一点,一些复杂的需求需要通过 Ingress 的 annotation 来实现,比如我们现在需要实现一个 url rewrite 的功能,简单来说就是我们之前的应用在 todo.qikqiak.com 下面,现在我们需要通过 todo.qikqiak.com/app/ 来进行访问。
前段时间阿里云和微软云联合发布了 Open Application Model(OAM),简单来说就是利用一个规范对应用程序进行建模以区分开发和运维人员的职责。开发人员负责描述微服务或组件的功能,以及如何配置它;运维负责配置其中一个或多个微服务的运行时环境;基础设施工程师负责建立和维护应用程序运行的基础设施。其中 Rudr 是针对 Kubernetes 上面的 OAM 的参考实现。
Rudr 的应用程序有三个元素:Components(组件)、Configuration(配置)、Traits(特征):
CPU、内存和存储等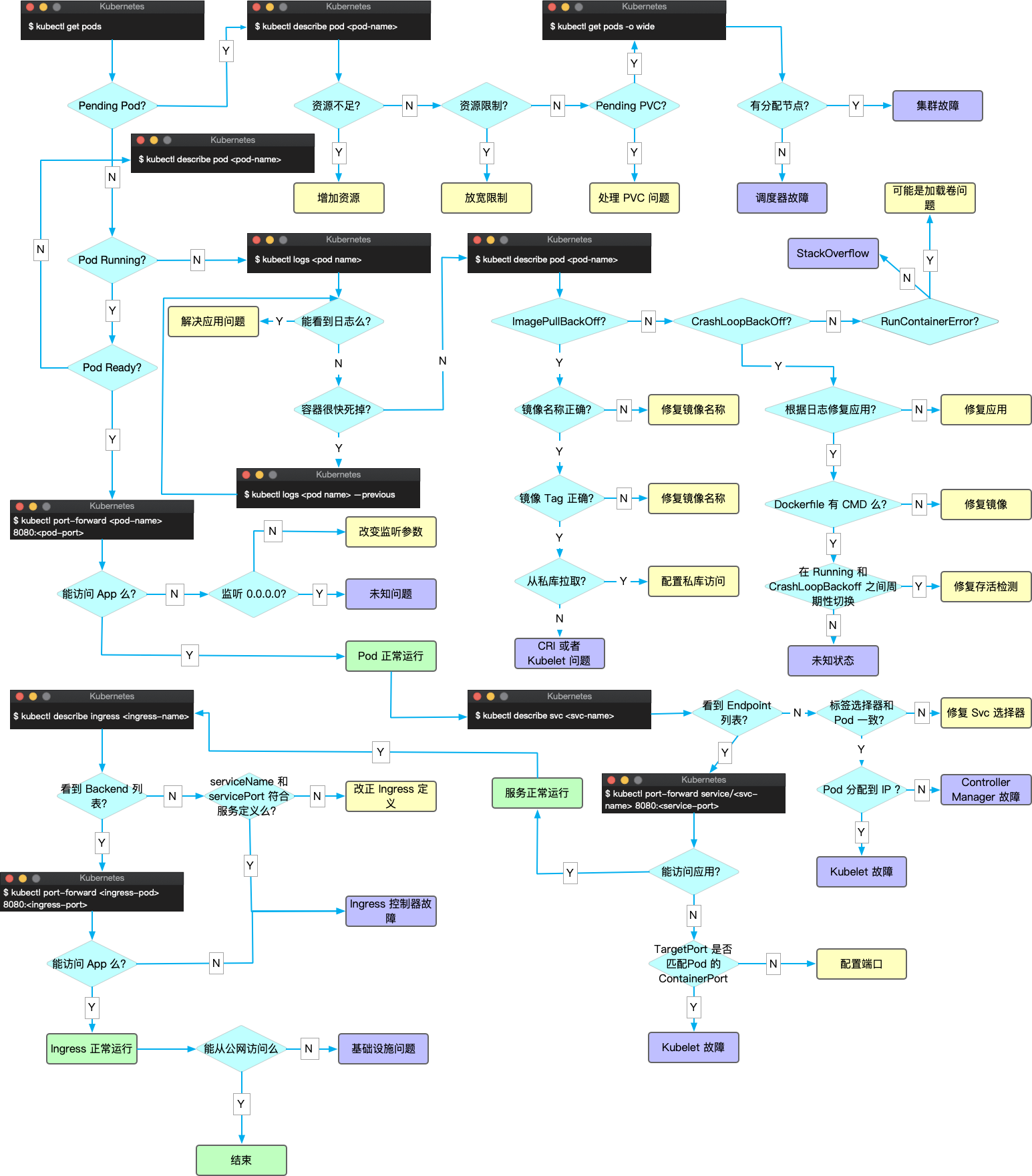{kind=link}