之前收集了很多优秀的PDF文档,但是需要看的时候不是很方便,需要去找到这个文件,如果是在手机上的话往往还需要下载PDF相关的插件才行,而且最大的问题是不便于资料的整理和分享。如果能够将PDF转换成网页,岂不是就能解决这些问题了?还能直接分享出去。
这里利用PyPDF包来处理PDF文件,为了方便快捷,我这里直接将一个页面转换成图片,就不需要去识别页面中的每一个PDF元素了,这是没必要的。
转换
核心代码很简单,就是将PDF文件读取出来,转换成PdfFileReader,然后就可以根据PyPDF2的API去获得每一个页面的二进制数据,拿到二进制数据过后,就能很方便的进行图片处理了,这里用wand包来进行图片处理。
# -*- coding: utf-8 -*-
import io
from wand.image import Image
from wand.color import Color
from PyPDF2 import PdfFileReader, PdfFileWriter
memo = {}
def getPdfReader(filename):
reader = memo.get(filename, None)
if reader is None:
reader = PdfFileReader(filename, strict=False)
memo[filename] = reader
return reader
def _run_convert(filename, page, res=120):
idx = page + 1
pdfile = getPdfReader(filename)
pageObj = pdfile.getPage(page)
dst_pdf = PdfFileWriter()
dst_pdf.addPage(pageObj)
pdf_bytes = io.BytesIO()
dst_pdf.write(pdf_bytes)
pdf_bytes.seek(0)
img = Image(file=pdf_bytes, resolution=res)
img.format = 'png'
img.compression_quality = 90
img.background_color = Color("white")
img_path = '%s%d.png' % (filename[:filename.rindex('.')], idx)
img.save(filename=img_path)
img.destroy()
需要注意的是一般PDF文件较大,如果一次性转换整个PDF文件需要小心内存溢出的问题,我们这里将第一次载入的整个PDF文件保存到内存,避免每次读取的时候都重新载入。
批量处理
上面已经完成了一个PDF页面的转换,要完成整个文件的转换就很简单了,只需要拿到文件的总页码,然后循环执行就行。考虑到转换比较耗时,可以使用异步处理的方式加快速度。比如可以使用celery来搭配处理,一定注意小心内存泄露。
核心代码已经整理放到github上去了,好了,等有时间的时候准备做一个公共的PDF转成H5的服务,开放给大众使用。
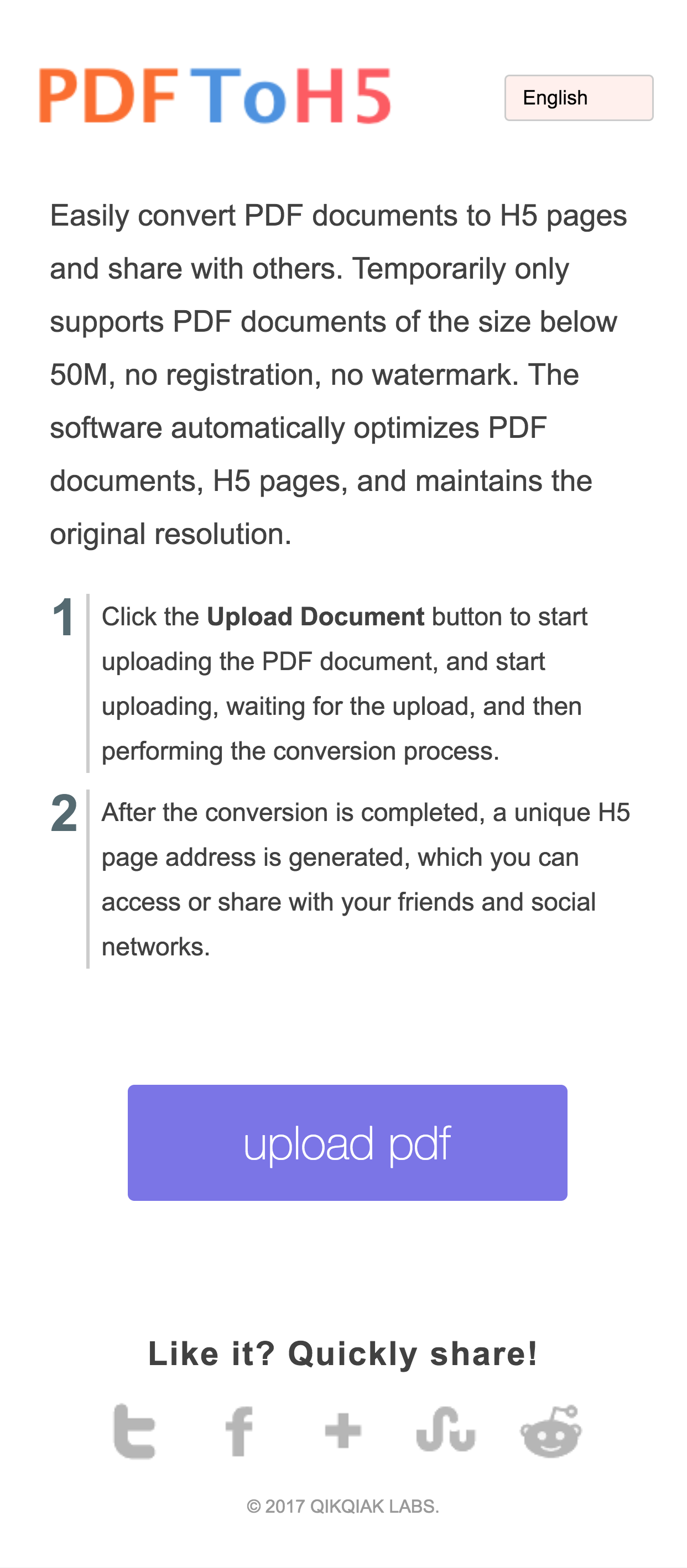
花了点时间,做成了一个独立的服务:https://pdfh5.com,欢迎大家试用
阳明和他朋友们的一些项目




微信公众号
扫描下面的二维码关注我们的微信公众帐号,在微信公众帐号中回复◉加群◉即可加入到我们的 kubernetes 讨论群里面共同学习。
