
日志和监控就像 Tony Stark 和他的 Iron Man 西装一样,两者需要一起使用才能发挥最大的威力,因为它们可以很好互补。
日志一直是应用程序和基础框架性能和故障诊断的重要手段,但是现在我们已经意识到日志不仅可以用于故障诊断,还可以用于大数据分析以及业务的一些可视化和性能分析等等。
所以,记录应用程序日志是非常非常重要的。
大家好,我叫阳明,前小米高级开发工程师,现在回到家乡成都,独立开发者一枚,一个有着产品思维的工程师,现在也在努力将自己的产品思维体系化,全栈工程师,现阶段专注 Kubernetes 和 AIGC,创建了「k8s技术圈」社区、「优点知识」知识付费网站以及「快课星球」AI全栈开发学习网站。我可以提供企业容器化方面的知识培训和咨询工作,感兴趣的可以通过微信 gitops 和我联系。




日志和监控就像 Tony Stark 和他的 Iron Man 西装一样,两者需要一起使用才能发挥最大的威力,因为它们可以很好互补。
日志一直是应用程序和基础框架性能和故障诊断的重要手段,但是现在我们已经意识到日志不仅可以用于故障诊断,还可以用于大数据分析以及业务的一些可视化和性能分析等等。
所以,记录应用程序日志是非常非常重要的。
刚刚发现一款看上去非常厉害的工具:icepanel,可以用来快速创建和可视化我们的 Kubernetes 微服务应用程序。使用也是非常简单,只需要安装一款 VSCODE 插件即可。
在前面文章中,我们在 Kubernetes 集群中安装了 Tekton,通过 Tekton 克隆 GitHub 代码仓库并执行了应用测试命令。接着前面的内容,本文我们将创建一个新的 Task 来构建一个 Docker 镜像并将其推送到 Docker Hub,最后,我们将这些任务组合成一个流水线。
Tekton 是一款功能非常强大而灵活的 CI/CD 开源的云原生框架。Tekton 的前身是 Knative 项目的 build-pipeline 项目,这个项目是为了给 build 模块增加 pipeline 的功能,但是随着不同的功能加入到 Knative build 模块中,build 模块越来越变得像一个通用的 CI/CD 系统,于是,索性将 build-pipeline 剥离出 Knative,就变成了现在的 Tekton,而 Tekton 也从此致力于提供全功能、标准化的云原生 CI/CD 解决方案。
本文将通过一个简单的示例来创建一个构建流水线,在流水线中将运行应用程序的单元测试、构建 Docker 镜像然后推送到 Docker Hub。
Dockerfile 是创建 Docker 镜像的起点,该文件提供了一组定义良好的指令,可以让我们复制文件或文件夹,运行命令,设置环境变量以及执行创建容器镜像所需的其他任务。编写 Dockerfile 来确保生成的镜像安全、小巧、快速构建和快速更新非常重要。
本文我们将看到如何编写良好的 Dockerfile 来加快开发流程,确保构建的可重用性,并生成可放心部署到生产中的镜像。
上节课和大家介绍了 Kubernetes 集群中的几种日志收集方案,Kubernetes 中比较流行的日志收集解决方案是 Elasticsearch、Fluentd 和 Kibana(EFK)技术栈,也是官方现在比较推荐的一种方案。
Elasticsearch 是一个实时的、分布式的可扩展的搜索引擎,允许进行全文、结构化搜索,它通常用于索引和搜索大量日志数据,也可用于搜索许多不同类型的文档。
Elasticsearch 通常与 Kibana 一起部署,Kibana 是 Elasticsearch 的一个功能强大的数据可视化 Dashboard,Kibana 允许你通过 web 界面来浏览 Elasticsearch 日志数据。
Fluentd是一个流行的开源数据收集器,我们将在 Kubernetes 集群节点上安装 Fluentd,通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到 Elasticsearch 集群,在该集群中对其进行索引和存储。
cdk8s 是 AWS Labs 发布的一个使用 TypeScript 编写的新框架,它允许我们使用一些面向对象的编程语言来定义 Kubernetes 的资源清单,cdk8s 最终也是生成原生的 Kubernetes YAML 文件,所以我们可以在任何地方使用 cdk8s 来定义运行的 Kubernetes 应用资源。
之前在解决 CoreDNS 的 5 秒超时问题的时候,除了通过 dnsConfig 去强制使用 tcp 方式解析之外,我们提到过使用 NodeLocal DNSCache 来解决这个问题。NodeLocal DNSCache 通过在集群节点上运行一个 DaemonSet 来提高 clusterDNS 性能和可靠性。处于 ClusterFirst 的 DNS 模式下的 Pod 可以连接到 kube-dns 的 serviceIP 进行 DNS 查询。通过 kube-proxy 组件添加的 iptables 规则将其转换为 CoreDNS 端点。通过在每个集群节点上运行 DNS 缓存,NodeLocal DNSCache 可以缩短 DNS 查找的延迟时间、使 DNS 查找时间更加一致,以及减少发送到 kube-dns 的 DNS 查询次数。
在前面的学习中我们使用用一个 kubectl scale 命令可以来实现 Pod 的扩缩容功能,但是这个毕竟是完全手动操作的,要应对线上的各种复杂情况,我们需要能够做到自动化去感知业务,来自动进行扩缩容。为此,Kubernetes 也为我们提供了这样的一个资源对象:Horizontal Pod Autoscaling(Pod 水平自动伸缩),简称HPA,HPA 通过监控分析一些控制器控制的所有 Pod 的负载变化情况来确定是否需要调整 Pod 的副本数量,这是 HPA 最基本的原理:

我们可以简单的通过 kubectl autoscale 命令来创建一个 HPA 资源对象,HPA Controller默认30s轮询一次(可通过 kube-controller-manager 的--horizontal-pod-autoscaler-sync-period 参数进行设置),查询指定的资源中的 Pod 资源使用率,并且与创建时设定的值和指标做对比,从而实现自动伸缩的功能。
Envoy 是为云原生应用而设计的开源边缘和服务代理,也是 Istio Service Mesh 默认的数据平面,本文我们通过一个简单的示例来介绍 Envoy 的基本使用。
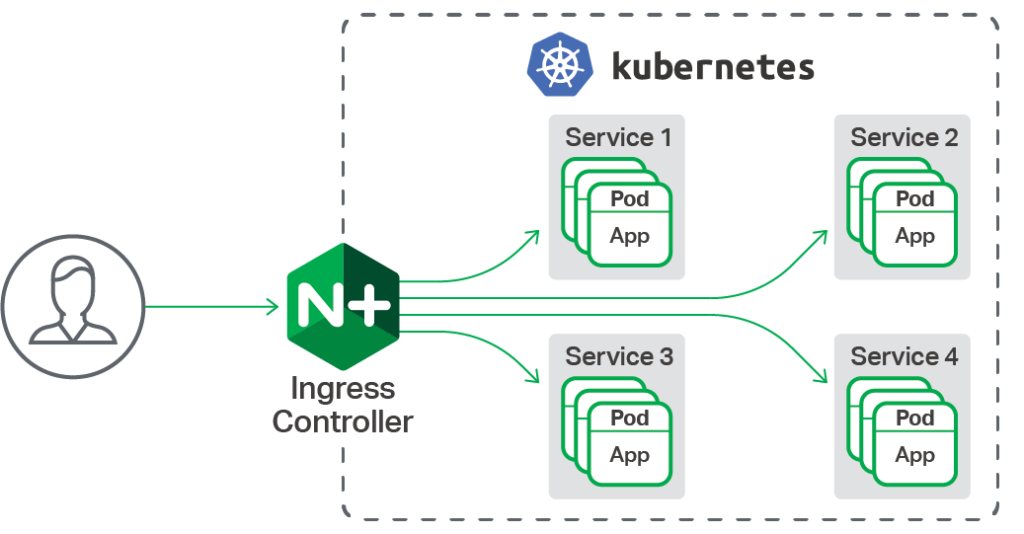
本文的目的是解释 Nginx Ingress 控制器的工作原理,特别是 Nginx 模型的构建方式以及我们为何需要这个模型。