Apache Kafka 是目前最流行的分布式消息发布订阅系统,虽然 Kafka 非常强大,但它同样复杂,需要一个高可用的强大平台来运行。在微服务盛行,大多数公司都采用分布式计算的今天,将 Kafka 作为核心的消息系统使用还是非常有优势的。
如果你在 Kubernetes 集群中运行你的微服务,那么在 Kubernetes 中运行 Kafka 集群也是很有意义的,这样可以利用其内置的弹性和高可用,我们可以使用内置的 Kubernetes 服务发现轻松地与集群内的 Kafka Pods 进行交互。
下面我们将来介绍下如何在 Kubernetes 上构建分布式的 Kafka 集群,这里我们将使用 Helm Chart 和 StatefulSet 来进行部署,当然如果想要动态生成持久化数据卷,还需要提前配置一个 StorageClass 资源,比如基于 Ceph RBD 的,如果你集群中没有配置动态卷,则需要提前创建 3 个未绑定的 PV 用于数据持久化。
当前基于 Helm 官方仓库的 chartincubator/kafka 在 Kubernetes 上部署的 Kafka,使用的镜像是 confluentinc/cp-kafka:5.0.1,即部署的是 Confluent 公司提供的 Kafka 版本,Confluent Platform Kafka(简称 CP Kafka)提供了一些 Apache Kafka 没有的高级特性,例如跨数据中心备份、Schema 注册中心以及集群监控工具等。
安装
使用 Helm Chart 安装当然前提要安装 Helm,直接使用最新版本的 Helm v3 版本即可:
> wget https://get.helm.sh/helm-v3.4.0-linux-amd64.tar.gz
> tar -zxvf helm-v3.4.0-linux-amd64.tar.gz
> sudo cp -a linux-amd64/helm /usr/local/bin/helm
> chmod +x /usr/local/bin/helm
然后添加 Kafka 的 Chart 仓库:
> helm repo add incubator http://mirror.azure.cn/kubernetes/charts-incubator/
> helm repo update
Hang tight while we grab the latest from your chart repositories...
...Successfully got an update from the "incubator" chart repository
...Successfully got an update from the "stable" chart repository
Update Complete. ⎈Happy Helming!⎈
接着我们就可以配置需要安装的 Values 文件了,可以直接使用默认的 values.yaml 文件,然后可以用它来进行定制,比如指定我们自己的 StorageClass:
> curl https://raw.githubusercontent.com/helm/charts/master/incubator/kafka/values.yaml > kfk-values.yaml
这里我直接使用默认的进行安装:
> helm install kafka incubator/kafka -f kfk-values.yaml
NAME: kafka
LAST DEPLOYED: Sun Nov 1 09:36:44 2020
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
### Connecting to Kafka from inside Kubernetes
You can connect to Kafka by running a simple pod in the K8s cluster like this with a configuration like this:
apiVersion: v1
kind: Pod
metadata:
name: testclient
namespace: default
spec:
containers:
- name: kafka
image: confluentinc/cp-kafka:5.0.1
command:
- sh
- -c
- "exec tail -f /dev/null"
Once you have the testclient pod above running, you can list all kafka
topics with:
kubectl -n default exec testclient -- ./bin/kafka-topics.sh --zookeeper kafka-zookeeper:2181 --list
To create a new topic:
kubectl -n default exec testclient -- ./bin/kafka-topics.sh --zookeeper kafka-zookeeper:2181 --topic test1 --create --partitions 1 --replication-factor 1
To listen for messages on a topic:
kubectl -n default exec -ti testclient -- ./bin/kafka-console-consumer.sh --bootstrap-server kafka:9092 --topic test1 --from-beginning
To stop the listener session above press: Ctrl+C
To start an interactive message producer session:
kubectl -n default exec -ti testclient -- ./bin/kafka-console-producer.sh --broker-list kafka-headless:9092 --topic test1
To create a message in the above session, simply type the message and press "enter"
To end the producer session try: Ctrl+C
If you specify "zookeeper.connect" in configurationOverrides, please replace "kafka-zookeeper:2181" with the value of "zookeeper.connect", or you will get error.
如果你没配置 StorageClass 或者可用的 PV,安装的时候 kafka 的 Pod 会处于 Pending 状态,所以一定要提前配置好数据卷。
正常情况隔一会儿 Kafka 就可以安装成功了:
> kubectl get pods
NAME READY STATUS RESTARTS AGE
kafka-0 1/1 Running 0 25m
kafka-1 1/1 Running 0 11m
kafka-2 1/1 Running 0 2m
kafka-zookeeper-0 1/1 Running 0 25m
kafka-zookeeper-1 1/1 Running 0 22m
kafka-zookeeper-2 1/1 Running 0 18m
默认会安装 3 个 ZK Pods 和 3 个 Kafka Pods,这样可以保证应用的高可用,也可以看下我配置的持久卷信息:
> kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
datadir-kafka-0 Bound kfk0 1Gi RWO 28m
datadir-kafka-1 Bound kfk1 1Gi RWO 13m
datadir-kafka-2 Bound kfk2 1Gi RWO 4m9s
> kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
kfk0 1Gi RWO Retain Bound default/datadir-kafka-0 23m
kfk1 1Gi RWO Retain Bound default/datadir-kafka-1 22m
kfk2 1Gi RWO Retain Bound default/datadir-kafka-2 10m
如果我们配置一个 default 的 StorageClass,则会动态去申请持久化卷,如果你的集群没有启用动态卷,可以修改 values.yaml 来使用静态卷。
然后查看下对应的 Service 对象:
> kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kafka ClusterIP 10.100.205.187 <none> 9092/TCP 31m
kafka-headless ClusterIP None <none> 9092/TCP 31m
kafka-zookeeper ClusterIP 10.100.230.255 <none> 2181/TCP 31m
kafka-zookeeper-headless ClusterIP None <none> 2181/TCP,3888/TCP,2888/TCP 31m
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 14d
可以看到又一个叫 kafka-zookeeper 的 zookeeper 服务和一个叫 kafka 的 Kafka 服务,对于 Kafka 集群的管理,我们将与 kafka-zookeeper 服务进行交互,对于集群消息的收发,我们将使用 kafka 服务。
客户端测试
现在 Kafka 集群已经搭建好了,接下来我们来安装一个 Kafka 客户端,用它来帮助我们产生和获取 topics 消息。
直接使用下面的命令创建客户端:
> cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: testclient
namespace: default
spec:
containers:
- name: kafka
image: confluentinc/cp-kafka:5.0.1
command:
- sh
- -c
- "exec tail -f /dev/null"
EOF
> kubectl get pod testclient
NAME READY STATUS RESTARTS AGE
testclient 1/1 Running 0 23s
客户端 Pod 创建成功后我们就可以开始进行一些简单的测试了。首先让我们创建一个名为 test1 的有一个分区和复制因子'1'的 topic:
> kubectl exec -it testclient -- /usr/bin/kafka-topics --zookeeper kafka-zookeeper:2181 --topic test1 --create --partitions 1 --replication-factor 1
Created topic "test1".
然后创建一个生产者,将消息发布到这个 topic 主题上:
> kubectl exec -ti testclient -- /usr/bin/kafka-console-producer --broker-list kafka:9092 --topic test1
>
然后重新打一个终端页面,让我们打开一个消费者会话,这样我们就可以看到我们发送的消息了。
> kubectl exec -ti testclient -- /usr/bin/kafka-console-consumer --bootstrap-server kafka:9092 --topic test1
现在我们在生产者的窗口发送消息,在上面的消费者会话窗口中就可以看到对应的消息了:
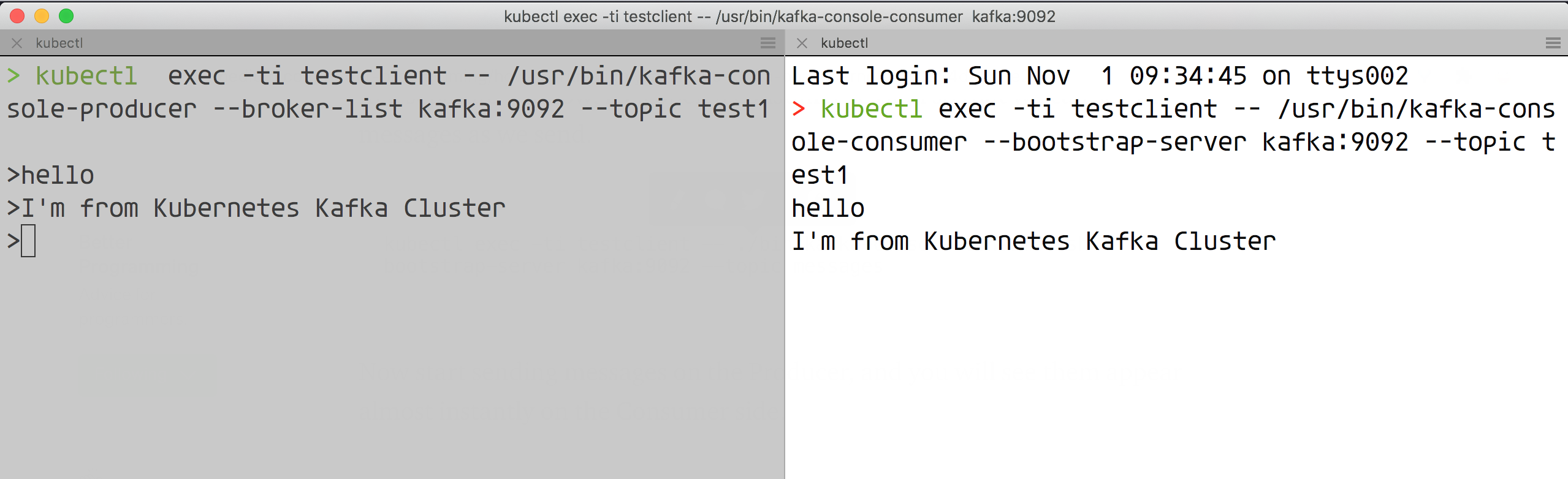
到这里证明 Kafka 集群就正常工作了。比如需要注意 zk 集群我们并没有做持久化,如果是生产环境一定记得做下数据持久化,在 values.yaml 文件中根据需求进行定制即可,当然对于生产环境还是推荐使用 Operator 来搭建 Kafka 集群,比如 strimzi-kafka-operator。
阳明和他朋友们的一些项目




微信公众号
扫描下面的二维码关注我们的微信公众帐号,在微信公众帐号中回复◉加群◉即可加入到我们的 kubernetes 讨论群里面共同学习。
