

虽然 Traefik 已经默认实现了很多中间件,可以满足大部分我们日常的需求,但是在实际工作中,用户仍然还是有自定义中间件的需求,为解决这个问题,官方推出了一个 Traefik Pilot 的功能了,此外在 Traefik v2.5 版本还推出了支持本地插件的功能。
大家好,我叫阳明,前小米高级开发工程师,现在回到家乡成都,独立开发者一枚,一个有着产品思维的工程师,现在也在努力将自己的产品思维体系化,全栈工程师,现阶段专注 Kubernetes 和 AIGC,创建了「k8s技术圈」社区、「优点知识」知识付费网站以及「快课星球」AI全栈开发学习网站。我可以提供企业容器化方面的知识培训和咨询工作,感兴趣的可以通过微信 gitops 和我联系。




虽然 Traefik 已经默认实现了很多中间件,可以满足大部分我们日常的需求,但是在实际工作中,用户仍然还是有自定义中间件的需求,为解决这个问题,官方推出了一个 Traefik Pilot 的功能了,此外在 Traefik v2.5 版本还推出了支持本地插件的功能。
随着 Kubernetes 的版本不断迭代发布,很多 Helm Chart 包压根跟不上更新的进度,导致在使用较新版本的 Kubernetes 的时候很多 Helm Chart 包不兼容,所以我们在开发 Helm Chart 包的时候有必要考虑到对不同版本的 Kubernetes 进行兼容。
前面我们有文章介绍过如何在 Kubernetes 集群中使用 GitLab CI 来实现 CI/CD,在构建镜像的环节我们基本上都是使用的 Docker On Docker 的模式,这是因为 Kubernetes 集群使用的是 Docker 这种容器运行时,所以我们可以将宿主机的 docker.sock 文件挂载到容器中构建镜像,而最近我们在使用 Kubernetes 1.22.X 版本后将容器运行时更改为了 Containerd,这样节点上没有可用的 Docker 服务了,这个时候就需要更改构建镜像的模式了,当然要实现构建镜像的方式有很多,我们这里还是选择使用 Docker 来构建我们的 Docker 镜像,也就是使用 Docker IN Docker 的模式。
在学习 Containerd 之前我们有必要对 Docker 的发展历史做一个简单的回顾,因为这里面牵涉到的组件实战是有点多,有很多我们会经常听到,但是不清楚这些组件到底是干什么用的,比如 libcontainer、runc、containerd、CRI、OCI 等等。
kube-vip 可以在你的控制平面节点上提供一个 Kubernetes 原生的 HA 负载均衡,我们不需要再在外部设置 HAProxy 和 Keepalived 来实现集群的高可用了。
kube-vip 是一个为 Kubernetes 集群内部和外部提供高可用和负载均衡的开源项目,在 Vmware 的 Tanzu 项目中已经使用 kube-vip 替换了用于 vSphere 部署的 HAProxy 负载均衡器,本文我们将先来了解 kube-vip 如何用于 Kubernetes 控制平面的高可用和负载均衡功能。
在 Kubernetes 中安全地运行工作负载是很困的,有很多配置都可能会影响到整个 Kubernetes API 的安全性,这需要我们有大量的知识积累来正确的实施。Kubernetes 在安全方面提供了一个强大的工具 securityContext,每个 Pod 和容器清单都可以使用这个属性。在本文中我们将了解各种 securityContext 的配置,探讨它们的含义,以及我们应该如何使用它们。
securityContext设置在PodSpec和ContainerSpec规范中都有定义,这里我们分别用[P]和[C]来表示。需要注意的是,如果一个设置在两个作用域中都可以使用和配置,那么我们应该优先考虑设置容器级别的。
多行日志(例如异常信息)为调试应用问题提供了许多非常有价值的信息,在分布式微服务流行的今天基本上都会统一将日志进行收集,比如常见的 ELK、EFK 等方案,但是这些方案如果没有适当的配置,它们是不会将多行日志看成一个整体的,而是每一行都看成独立的一行日志进行处理,这对我们来说是难以接受的。
在本文中,我们将介绍一些常用日志收集工具处理多行日志的策略。
go1.16 版本已经 release 了,推出了一些新功能特性,其中有一个 embed 的新功能,通过 embed 可以将静态资源文件直接打包到二进制文件中,这样当我们部署 Web 应用的时候就特别方便了,只需要构建成一个二进制文件即可,以前也有一些第三方的工具包可以支持这样的操作,但是毕竟不是官方的。接下来我们就来为大家简单介绍下 embed 功能的基本使用。

[前面我们已经介绍了 Kubernetes 社区内部为 Kubernetes 开发了一种改进的定义和管理入口流量的新接口](* Kubernetes Service APIs 简介),也就是新的 Kubernetes Service APIs。Traefik 在 2.4 版本中引入了对 Service APIs 的初始支持。本文我们将演示如何通过 Traefik 来使用新的 Gateway、GatewayClass 和 HTTPRoute API 将请求路由到后端的服务 Pod。
Kubernetes 服务 APIs(Service APIs)是由 SIG-NETWORK 社区管理的开源项目,项目地址:https://github.com/kubernetes-sigs/service-apis。该项目的目标是在 Kubernetes 生态系统中发展服务网络 API,服务 API 提供了暴露 Kubernetes 应用的接口 - Services、Ingress 等。
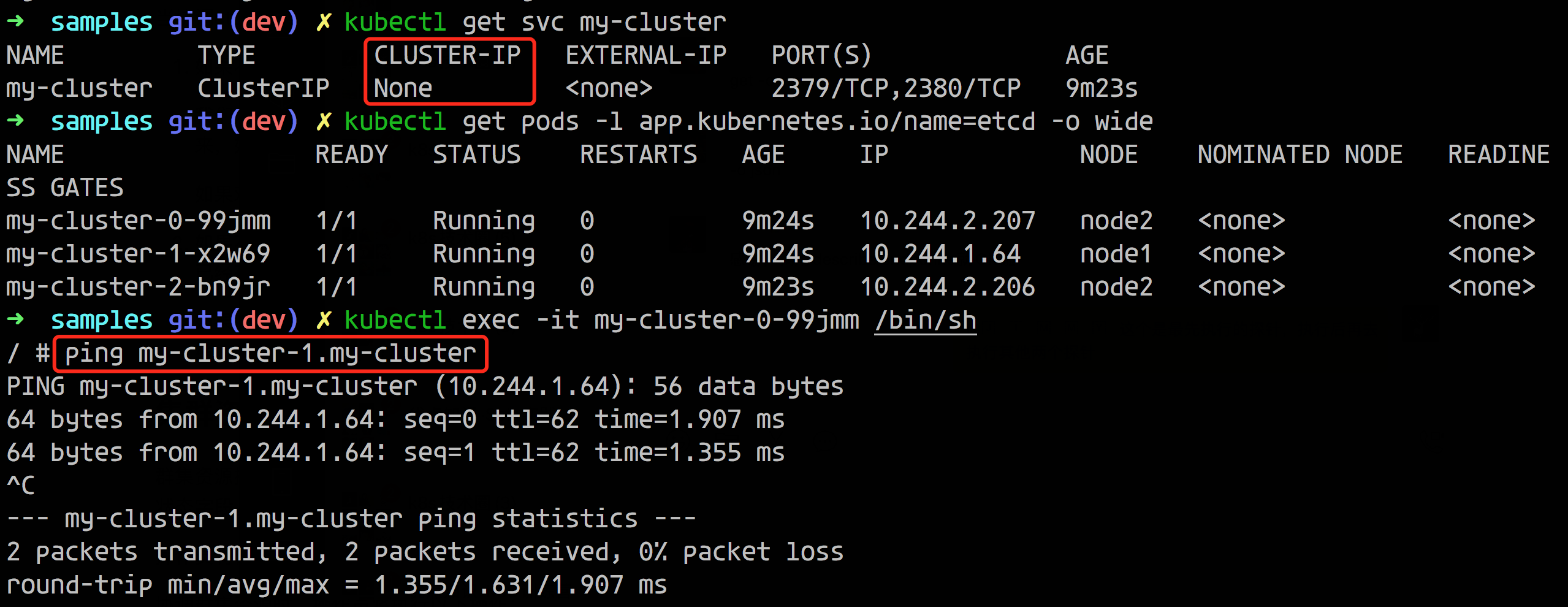
我们都知道 StatefulSet 中的 Pod 是拥有单独的 DNS 记录的,比如一个 StatefulSet 名称为 etcd,而它关联的 Headless SVC 名称为 etcd-headless,那么 CoreDNS 就会为它的每个 Pod 解析如下的 A 记录:
那么除了 StatefulSet 管理的 Pod 之外,其他的 Pod 是否也可以生成 DNS 记录呢?
如下所示,我们这里只有一个 Headless 的 SVC,并没有 StatefulSet 管理的 Pod,而是 ReplicaSet 管理的 Pod,我们可以看到貌似也生成了类似于 StatefulSet 中的解析记录。
如果你使用过 Docker 和 Kubernetes,那么可能应该听说过 network namespace(网络命名空间),最近在我们的 《Kubernetes 网络训练营》课程中学习到了 Linux 下面的 ip 命令的使用,本文我将演示如何使用命令通过一对 veth 接口连接不同子网中的网络命名空间的进程。