VictoriaLogs 是一个相对较新的日志收集和分析系统,类似于 Grafana Loki,就像 VictoriaMetrics 相对于普通 Prometheus 一样,对 CPU/内存资源的需求较少。
就我个人而言,我使用 Grafana Loki 大约 5 年了,但有时我对它有些担忧,无论是在文档方面还是系统的整体复杂性方面,因为有很多组件。此外,在性能方面也有一些问题,因为无论我如何尝试调整它,有时在相对较小的查询上,Grafana 仍然从 Loki 网关返回 504 错误,我真的厌倦了处理这个问题。
由于我项目中的监控是基于 VictoriaMetrics 构建的,并且 VictoriaLogs 已经获得了 Grafana 数据源支持,现在是时候尝试一下并与 Grafana Loki 进行比较了。
首先,请记住 VictoriaLogs 仍处于 Beats 状态,并且尚未具备:
- 不支持 AWS S3 后端——但他们承诺将在 2024 年 11 月实现(通过一些“神奇”的自动化——本地磁盘上的旧数据将自动移动到相应的 S3 )
- Loki RecordingRules 还没有类似的功能——当我们从日志中创建常规指标,然后将它们推送到 VictoriaMetrics/Prometheus,然后在 VMAlert 和/或 Grafana 中创建警报和仪表板,但这应该很快——2024 年 10 月至 11 月
- Grafana 数据源仍处于 Beta 阶段,因此在 Grafana 中绘图存在困难
VictoriaLogs 文档——就像在 VictoriaMetrics 中一样——有出色的文档。
那么我们今天要做什么?
- 在 Kubernetes 中启动 VictoriaLogs
- 看看其 LogsQL 的功能
- 连接 Grafana 数据源
- 将了解如何在 Grafana 中创建仪表板
VictoriaLogs Helm Chart
我们将从 vm/victoria-logs-single Helm-chart 部署。
VictoriaLogs 也在 VictoriaMetrics Operator 中得到支持(参见 VLogs)。
在我的项目中,我们使用自己的图表进行监控,其中通过 Helm 依赖安装了 victoria-metrics-k8s-stack chart 和一些额外的服务,如 Promtail、k8s-event-logger 等。让我们将 victoria-logs-single 添加到同一个 chart 中。
首先,我们将手动完成所有操作,先使用一些默认值,然后我们将查看它在 Kubernetes 中安装了什么以及如何工作,最后我们将其添加到自动化中。
在 VictoriaLogs Chart 中,有一个运行 Fluentbit DaemonSet 的选项,但我们已经有 Promtail,所以我们将使用它。
所有 values 都在图表文档中可用,但以下内容可能现在会引起兴趣:
extraVolumeMounts和extraVolumes:我们可以使用 AWS EBS 创建我们自己的专用persistentVolume并将其连接到 VictoriaLogs 以存储我们的日志persistentVolume.enabled和persistentVolume.storageClassName:或者我们可以简单地指定它应该被创建,并在必要时使用 ReclaimPolicyretain设置我们自己的storageClass- 在我的情况下,一些日志是用 AWS Lambda 编写的,因此需要创建一个内部类型的 AWS ALB
安装 Chart
添加存储库:
$ helm repo add vm https://victoriametrics.github.io/helm-charts/
$ helm repo update
在单独的 Kubernetes 命名空间 ops-test-vmlogs-ns 中安装 chart:
$ helm -n ops-test-vmlogs-ns upgrade --install vlsingle vm/victoria-logs-single
检查 Kubernetes Pod 在那里:
$ kk get pod
NAME READY STATUS RESTARTS AGE
vlsingle-victoria-logs-single-server-0 1/1 Running 0 36s
让我们看看 Pod 使用的资源:
$ kk top pod
NAME CPU(cores) MEMORY(bytes)
vlsingle-victoria-logs-single-server-0 1m 3Mi
3Mi 的内存 :-)
展望未来,将 Promtail 的日志连接到 VictoriaLogs 后,它不会使用更多的资源。
让我们打开对 VM UI 的访问权限:
$ kk -n ops-test-vmlogs-ns port-forward svc/vlsingle-victoria-logs-single-server 9428
在浏览器中,访问 http://localhost:9428。
与 VictoriaMetrics 的其他服务一样,您将被带到一个包含所有必要链接的页面:
让我们去 http://localhost:9428/select/vmui/ — 目前它是空的:
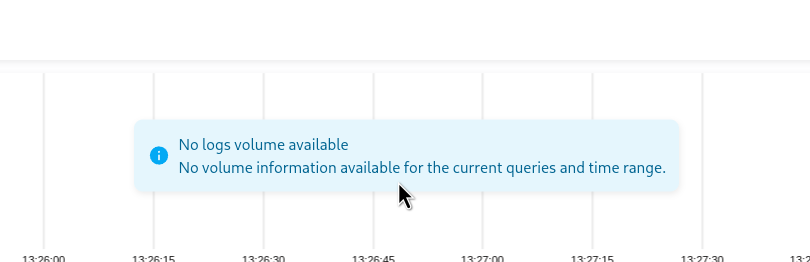
让我们添加从 Promtail 发送日志。
配置 Promtail
您可以将日志写入 VictoriaLogs,格式为 Elasticsearch、ndjson 或 Loki。
我们实际上对 Loki 感兴趣,并且我们使用 Promtail 编写日志。有关 VictoriaLogs 的 Promtail 配置示例,请参阅 Promtail 设置。
在我们的案例中,Promtail 是从其自己的 chart 中安装的,并使用 promtail.yml 配置文件创建一个 Kubernetes Secret。
更新 values 值,向 config.clients 添加另一个 URL - 在我的场景下,它将使用命名空间 ops-test-vmlogs-ns.svc ,因为 VictoriaLogs 运行在与 Loki 不同的命名空间中:
...
promtail:
config:
clients:
- url: http://atlas-victoriametrics-loki-gateway/loki/api/v1/push
- url: http://vlsingle-victoria-logs-single-server.ops-test-vmlogs-ns.svc:9428/insert/loki/api/v1/push
...
部署更改,等待 Promtail 的 pod 重启,然后再次检查 VictoriaLogs 中的日志:

VictoriaLogs 日志流
当将日志写入 VictoriaLogs 时,我们可以设置其他参数。
现在可能有趣的一件事是尝试创建自己的日志流,以便更快地处理日志。
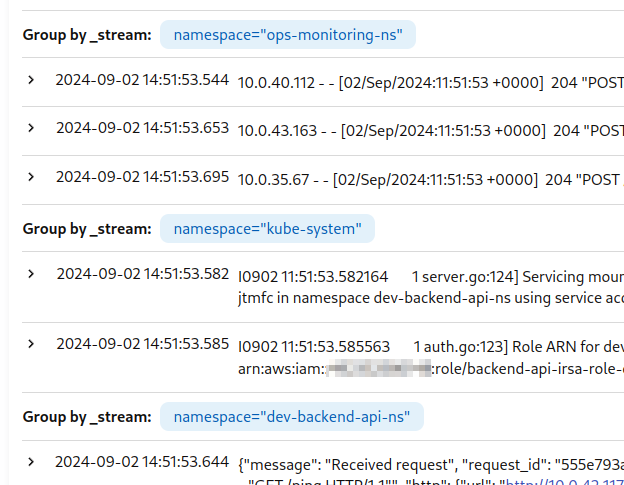
如果未指定日志流,则 VictoriaLogs 会将所有内容写入一个默认流 {} ,如上面的截图所示。
例如,在我们的集群中,所有应用程序都被划分到各自的 Kubernetes 命名空间 — dev-backend-api-ns、prod-backend-api-ns、ops-monitoring-ns 等。
让我们为每个命名空间创建一个单独的流 — 将 ?_stream_fields=namespace 添加到 url :
...
config:
clients:
- url: http://atlas-victoriametrics-loki-gateway/loki/api/v1/push
- url: http://vlsingle-victoria-logs-single-server.ops-test-vmlogs-ns.svc:9428/insert/loki/api/v1/push?_stream_fields=namespace
...
部署它,现在我们为每个命名空间提供了单独的流:
VictoriaLogs vs Loki:CPU/内存资源
让我们来看看所有 Loki Pods 当前消耗的资源:
$ kk -n ops-monitoring-ns top pod | grep loki
atlas-victoriametrics-loki-chunks-cache-0 2m 824Mi
atlas-victoriametrics-loki-gateway-6bd7d496f5-9c2fh 1m 12Mi
atlas-victoriametrics-loki-results-cache-0 1m 32Mi
loki-backend-0 50m 202Mi
loki-backend-1 8m 214Mi
loki-backend-2 12m 248Mi
loki-canary-gzjxh 1m 15Mi
loki-canary-h9d6s 1m 17Mi
loki-canary-hkh4f 2m 17Mi
loki-canary-nh9mf 2m 16Mi
loki-canary-pbs4x 1m 17Mi
loki-read-55bcffc9fb-7j4tg 12m 255Mi
loki-read-55bcffc9fb-7qtns 45m 248Mi
loki-read-55bcffc9fb-s7rpq 10m 244Mi
loki-write-0 42m 262Mi
loki-write-1 27m 261Mi
loki-write-2 26m 258Mi
和 VictoriaLogs 资源:
$ kk top pod
NAME CPU(cores) MEMORY(bytes)
vlsingle-victoria-logs-single-server-0 2m 14Mi
尽管记录的日志数量相同。
是的,Loki 现在有一堆 RecordingRules,是的,Grafana 中有几个仪表板直接向 Loki 请求图表,但差别是巨大的!
也许是我比较笨拙无法正确调试 Loki——但 VictoriaLogs 现在无需任何调整就能运行。
LogsSQL
现在我们有了 VictoriaLogs 实例,我们有写入其中的日志。
让我们尝试从日志中查询一些数据,并与 Loki 的 LogQL 进行一些比较。我们可以从 VM UI、CLI 和 Grafana 进行查询。
使用 HTTP API 进行查询
VictoriaLogs 有一个非常好的 API,可以用来获取你需要的所有数据。
例如,要使用 curl 搜索日志,我们可以向 /select/logsql/query 发出查询,然后通过 UNIX 管道将其传递给 jq 。
我们仍在运行 kubectl port-forward ,所以让我们查询所有包含“error”字样的日志:
$ curl -s localhost:9428/select/logsql/query -d 'query=error' | head | jq
{
"_time": "2024-09-02T12:23:40.890465823Z",
"_stream_id": "0000000000000000195443555522d86dcbf56363e06426e2",
"_stream": "{namespace=\"staging-backend-api-ns\"}",
"_msg": "[2024-09-02 12:23:40,890: WARNING/ForkPoolWorker-6] {\"message\": \"Could not execute transaction\", \"error\": \"TransactionCanceledException('An error occurred (TransactionCanceledException) when calling the TransactWriteItems operation: Transaction cancelled, please refer cancellation reasons for specific reasons [None, None, ConditionalCheckFailed]')\", \"logger\": \"core.storage.engines.dynamodb_transactions\", \"level\": \"warning\", \"lineno\": 124, \"func_name\": \"_commit_transaction\", \"filename\": \"dynamodb_transactions.py\", \"pid\": 2660, \"timestamp\": \"2024-09-02T12:23:40.890294\"}",
"app": "backend-celery-workers",
"component": "backend",
"container": "backend-celery-workers-container",
"filename": "/var/log/pods/staging-backend-api-ns_backend-celery-workers-deployment-66b879bfcc-8pw52_46eaf32d-8956-4d44-8914-7f2afeda41ad/backend-celery-workers-container/0.log",
"hostname": "ip-10-0-42-56.ec2.internal",
"job": "staging-backend-api-ns/backend-celery-workers",
"logtype": "kubernetes",
"namespace": "staging-backend-api-ns",
"node_name": "ip-10-0-42-56.ec2.internal",
"pod": "backend-celery-workers-deployment-66b879bfcc-8pw52",
"stream": "stderr"
}
...
因此,我们拥有所有字段和上面设置的日志流 — 按 namespace 字段。
另一个有趣的端点是能够在日志中获取包含关键字的所有流,例如:
$ curl -s localhost:9428/select/logsql/streams -d "query=error" | jq
{
"values": [
{
"value": "{namespace=\"ops-monitoring-ns\"}",
"hits": 5012
},
{
"value": "{namespace=\"staging-backend-api-ns\"}",
"hits": 542
},
...
来自 VM UI 的查询
一切都很简单:在日志查询字段中编写查询,然后获取结果。
您可以以分组、表格和 JSON 格式获取结果。我们已经在 HTTP API 中看到过 JSON 格式。
在“按组显示”格式中,结果会显示在每个流中:

在表格格式中 — 按日志中的字段名称分列:

LogsQL 基本语法
我们已经看到了 LogsQL 查询的最简单示例——只需使用“error”这个词。
要搜索一个短语,请用引号将其括起来:
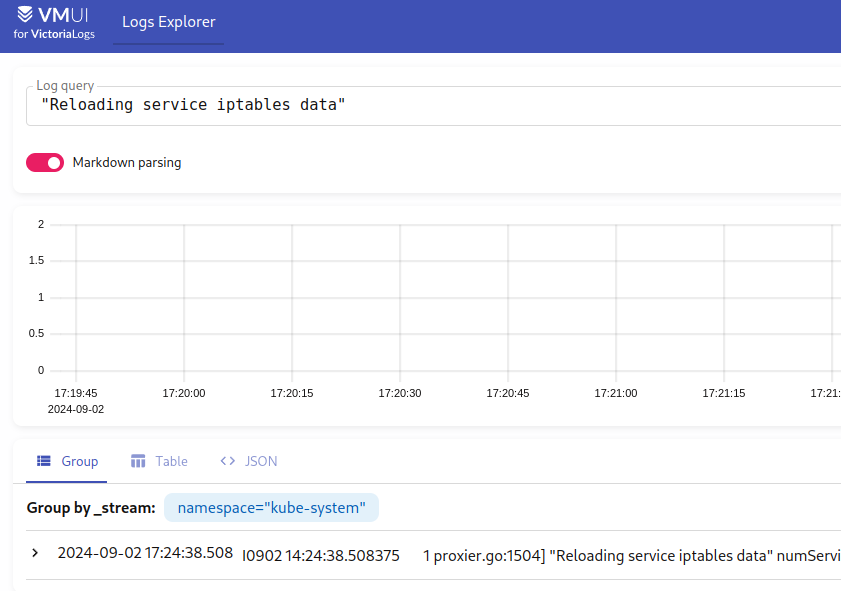
结果排序
一个重要的注意事项是,为了提高性能,结果是以随机顺序返回的,因此建议使用管道 sort 按 _time 字段:
_time:5m error | sort by (_time)
注释
我们可以在请求中添加注释,这真的很酷,例如:
_time:5m | app:="backend-api" AND namespace:="prod-backend-api-ns" # this is a comment
| unpack_json | keep path, duration, _msg, _time # and an another one comment
| stats by(path) avg(duration) avg_duration | path:!"" | limit 10
操作符
在 LogsSQL 中,它们被称为逻辑过滤器 — AND , OR , NOT 。
例如,我们可以以下列方式使用 AND :我们正在寻找包含字符串"Received request"和 ID"dada85f9246d4e788205ee1670cfbc6f"的记录:
"Received request" AND "dada85f9246d4e788205ee1670cfbc6f"
或仅从 namespace="prod-backend-api-ns" 流中搜索“Received request”:
"Received request" AND _stream:{namespace="prod-backend-api-ns"}
或者通过 pod 字段:
"Received request" AND pod:="backend-api-deployment-98fcb6bcb-w9j26"
顺便说一下, AND 运算符可以省略,因此查询:
"Received request" pod:="backend-api-deployment-98fcb6bcb-w9j26"
将以与前一个相同的方式处理。
但在下面的例子中,我仍然会添加 AND 以便清晰。
过滤器
任何 LogsQL 查询必须至少包含一个过滤器。
当我们进行类似“Received request”的查询时,我们实际上使用了短语过滤器,该过滤器默认应用于 _msg 字段。
在 _stream:{namespace="prod-backend-api-ns"} 请求中,我们使用 Stream 过滤器。
其他有趣的过滤器:
- 时间过滤器 — 您可以设置时间段为分钟/小时或日期
- Day 和 Week 范围过滤器 — 或按特定日期或星期几搜索
- 前缀过滤器 — 搜索不完整的单词或短语
- 不区分大小写的过滤器——不区分大小写的搜索
- 正则表达式过滤器 — 搜索中的正则表达式
- IPv4 范围过滤器——很棒的功能——一个现成的 IP 地址过滤器
让我们快速看几个例子。
时间过滤器
选择所有最后时刻的条目:
"Received request" AND _time:1m
或者 2024 年 9 月 1 日:
"Received request" AND _time:2024-09-01
或在包括 8 月 30 日至 9 月 2 日的期间:
"Received request" AND _time:[2024-08-30, 2024-09-02]
或者没有 2024–08–30 的条目——也就是说,从 31 日开始——将 [ 更改为 ( :
"Received request" AND _time:(2024-08-30, 2024-09-02]
日范围过滤器
按一天中的小时过滤。
例如,今天 14:00 到 18:00 之间的所有记录:
"Received request" AND _time:day_range[14:00, 18:00]
类似于时间过滤器——使用 () 和 [] 来包含或排除范围的开始或结束。
周范围过滤器
与“日范围”过滤器类似,但按星期几过滤:
"Received request" AND _time:week_range[Mon, Fri]
前缀过滤器
使用 "*" 表示我们需要所有以"ForkPoolWorker-1"开头的日志,即所有工作编号为 1、12、19 等的日志:
"ForkPoolWorker-1"*
同样,我们可以使用此过滤器来过滤记录字段中的值。
例如,选择所有 container 字段值为“backend-celery”的记录:
app:"backend-celery-"*
或者您可以使用 Substring 过滤器:
app:~"backend-celery"
正则表达式过滤器
正则表达式搜索也可以与子字符串过滤器结合使用。
例如,查找所有包含“Received request”或“ForkPoolWorker”的记录:
~"Received request|ForkPoolWorker"
管道
在 LogsQL 中另一个有趣的功能是使用管道,通过它可以执行额外的操作。
例如,在 Grafana 中,我经常需要重命名指标或日志中的字段名称。
使用 LogsSQL,可以通过 | copy 或 | rename 完成:
- 有一个字段
logtype: kubernetes - 我们想让它成为
source: kubernetes
运行以下查询:
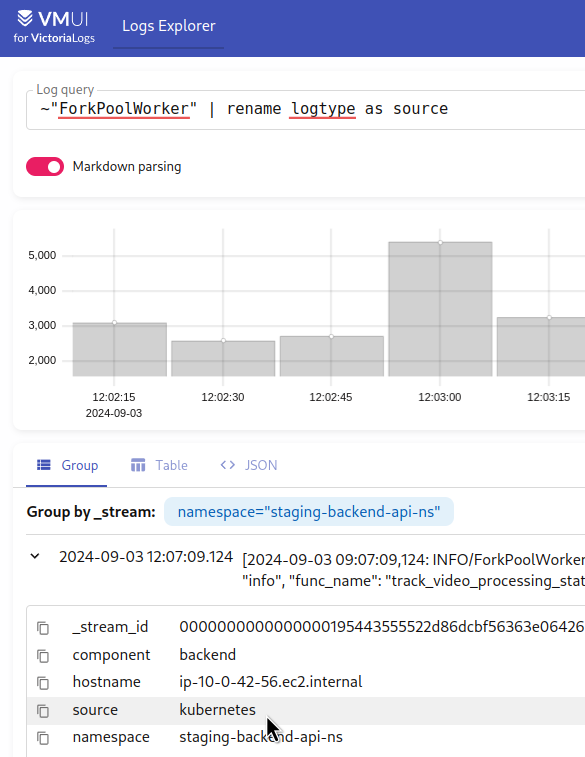
~"ForkPoolWorker" | rename logtype as source
并检查结果中的字段:
其他有趣的管道:
delete管道:从结果中移除一个字段extract管道:使用日志中的值创建一个新字段field_names管道:返回所有带有记录数的字段fields管道:仅在结果中返回选定字段filter管道:使用附加条件过滤结果limit管道:仅显示指定数量的结果(另请参见top)math管道:执行数学运算offset管道:也是一个很酷的东西 - 通过指定的时间段进行“偏移”pack_json管道:将结果中的所有字段“打包”成 JSON(另请参见pack_logfmt和unpack_json)replace管道:用另一个词/短语替换结果中的一个词/短语(例如,掩盖密码)sort管道:对结果进行排序操作stats管道:显示统计数据
我不会在这里描述这些示例,因为它们通常在文档中可以找到,但让我们看看一个针对 Loki 的示例查询,并尝试为 VictoriaLogs 重写它,在那里我们将尝试使用管道。
示例:Loki 到 VictoriaLogs 查询
我们有一个关于 Loki RecordingRules 的查询:
- record: eks:pod:backend:api:path_duration:avg
expr: |
topk (10,
avg_over_time (
{app="backend-api"} | json | regexp "https?://(?P<domain>([^/]+))" | line_format "{{.path}}: {{.duration}}" | unwrap duration [5m]
) by (domain, path, node_name)
)
从我们的后端 API Pods 的 Kubernetes Pods 日志中,规则创建了 eks:pod:backend:api:path_duration:avg 指标,该指标显示每个端点的平均响应时间。
在这里我们有:
- 从
app="backend-api"日志流中选择日志 - 日志是用 JSON 格式编写的,所以我们使用
json解析器 - 然后使用
regex解析器,我们创建一个domain字段,其值在"https://“之后 - 使用
line_format我们得到path和duration字段 - 使用
unwrap从duration中“提取”值 - 从
duration中使用avg_over_time()运算符计算过去 5 分钟的平均值,按domain、path、node_name字段分组 - 然后将它们用于 Grafana 警报和图表中 - 收集前 10 条记录的信息
我们如何使用 VictoriaLogs 及其 LogsQL 做类似的事情?
让我们从字段过滤器开始:
app:="backend-api"
在这里我们从后端 API 应用程序获取所有记录。
请记住,我们可以在这里使用正则表达式,并将过滤器设置为 app:~"backend" - 然后我们将获得带有 app="backend-celery-workers" 、 app="backend-api 等的结果。
您可以按流添加过滤器——仅来自生产:
_stream:{namespace="prod-backend-api-ns"} AND app:="backend-api"
或者只是:
namespace:="prod-backend-api-ns" AND app:="backend-api"
在我们的 Loki 指标中,我们不使用 namespace 字段,因为警报和 Grafana 中的过滤器使用 domain 字段中的域名,但在这里为了示例和清晰起见,让我们添加它。
接下来,我们需要创建 domain 、 path 和 duration 字段。
在这里,我们可以使用 unpack_json 或 extract 。
unpack_json 将解析 JSON 并从 JSON 中的每个键创建记录字段:
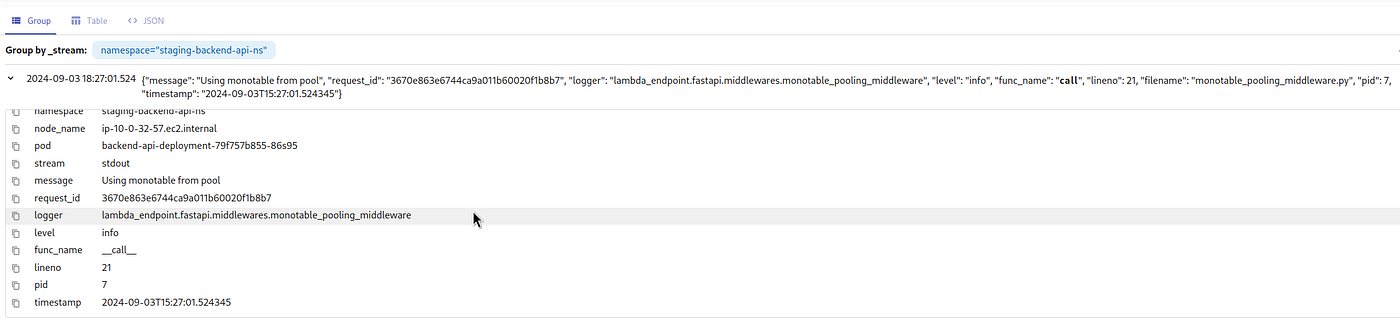
unpack_json的文档说最好使用extract管道- 如果使用它,请求将是
| extract '"duration": <duration>,'
但是我们不需要所有字段,所以我们可以删除它们,只保留 duration 、 _msg 和 _time ,并使用 keep 过滤器:

接下来,我们需要创建一个 domain 字段。但仅仅从 {"url": "http://api.app.example.co/coach/notifications?limit=0" ...} 中获取由 unpack_json 创建的 url 键对我们来说不起作用,因为我们只需要域名 - 不包括“/coach/notifications?limit=0”URI。
为了解决这个问题,我们可以添加 extract_regexp 过滤器 - extract_regexp "https?://(?P<domain>([^/]+))" :

现在我们有了所有三个字段,我们可以通过 duration 字段使用 stats by() 和 avg :
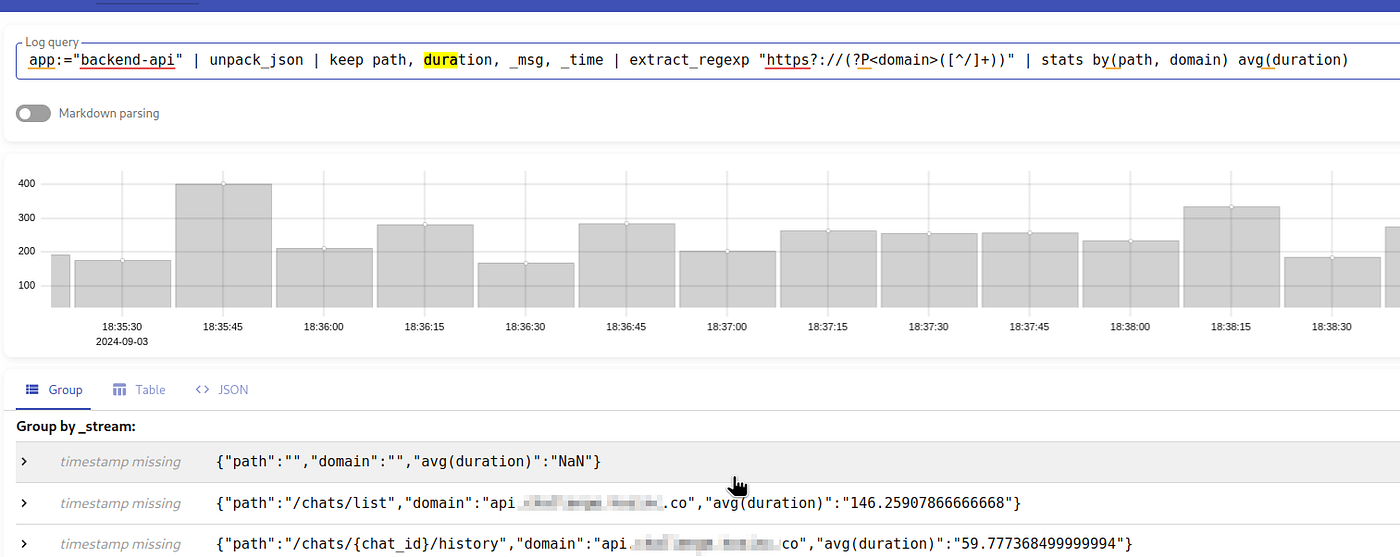
要从结果中移除 {"path":"", "domain":"", "avg(duration)": "NaN"} ,请添加 path:!"" 过滤器。
现在整个查询将是:
app:="backend-api" | unpack_json | keep path, duration, _msg, _time | extract_regexp "https?://(?P<domain>([^/]+))" | stats by(path, domain) avg(duration) | path:!""
最后,我们添加最后 5 分钟的限制 — _time:5m ,并仅显示前 10 个结果。
我将在此处移除 domain 并添加 namespace 过滤器,以便更容易与 Loki 中的结果进行比较。
我们将把 avg(duration) 的结果写入新字段 avg_duration 。
现在整个查询将是这样的:
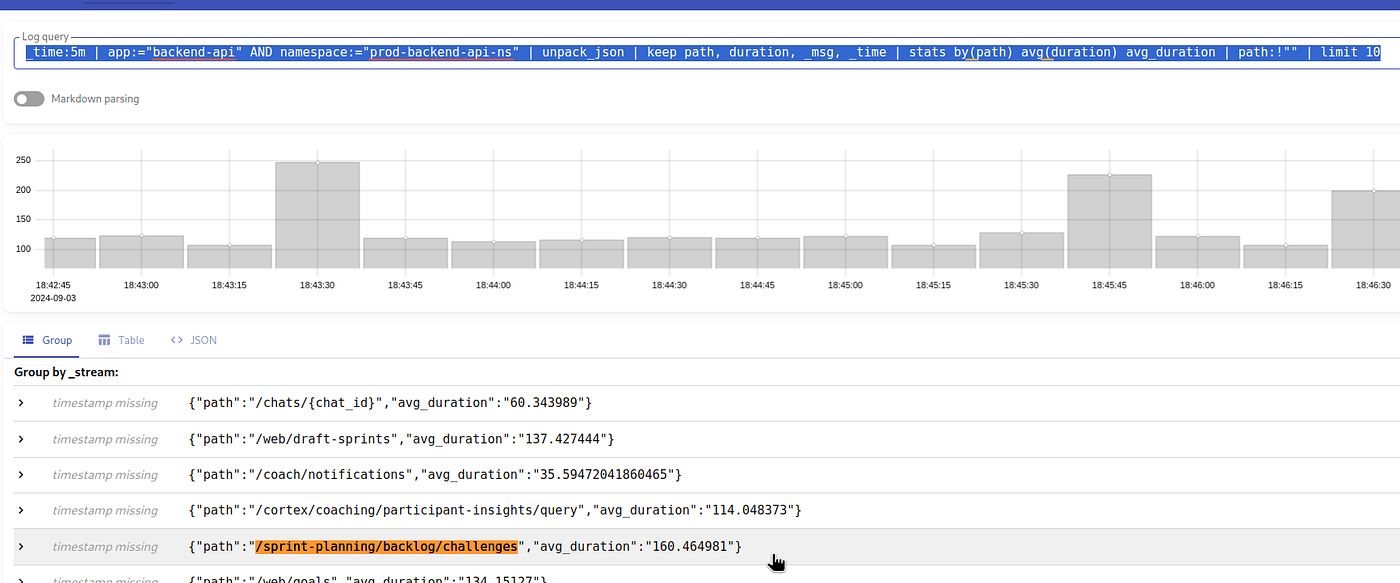
_time:5m | app:="backend-api" AND namespace:="prod-backend-api-ns" | unpack_json | keep path, duration, _msg, _time | stats by(path) avg(duration) avg_duration | path:!"" | limit 10
结果是:
与其使用 limit ,不如使用 top 管道 - 因为 limit 只是限制请求的数量,而 top 则通过字段的值来限制:
_time:5m | app:="backend-api" AND namespace:="prod-backend-api-ns" | unpack_json | keep path, duration, _msg, _time | stats by(path) avg(duration) avg_duration | path:!"" | top 10 by (path, duration)
我们可以添加 sort() ,并在调用 stats( ) 之前放置 path:!"" 条件,以加快请求处理速度:
_time:5m | app:="backend-api" AND namespace:="prod-backend-api-ns" | unpack_json | keep path, duration, _msg, _time | path:!"" | stats by(path) avg(duration) avg_duration | sort by (_time, avg_duration) | top 10 by (path, avg_duration)
让我们将其与 Loki 的结果进行比较,例如,VictoriaLogs 结果中的 API 端点 /sprint-planning/backlog/challenges 的值为 160.464981 毫秒。
在 Loki 中运行类似的查询:
topk (10,
avg_over_time (
{app="backend-api", namespace="prod-backend-api-ns"} | __error__="" | json | line_format "{{.path}}: {{.duration}}" | unwrap duration [5m]
) by (path)
)
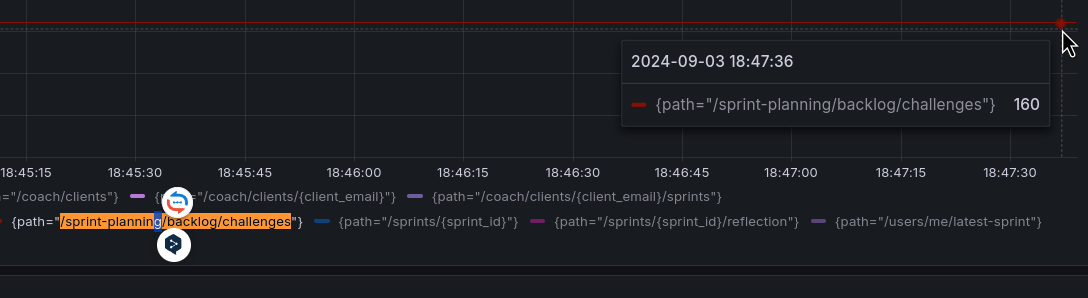
看起来不错。
ChatGPT、Gemini、Claude 和 LogsSQL(还有 Perplexity!)
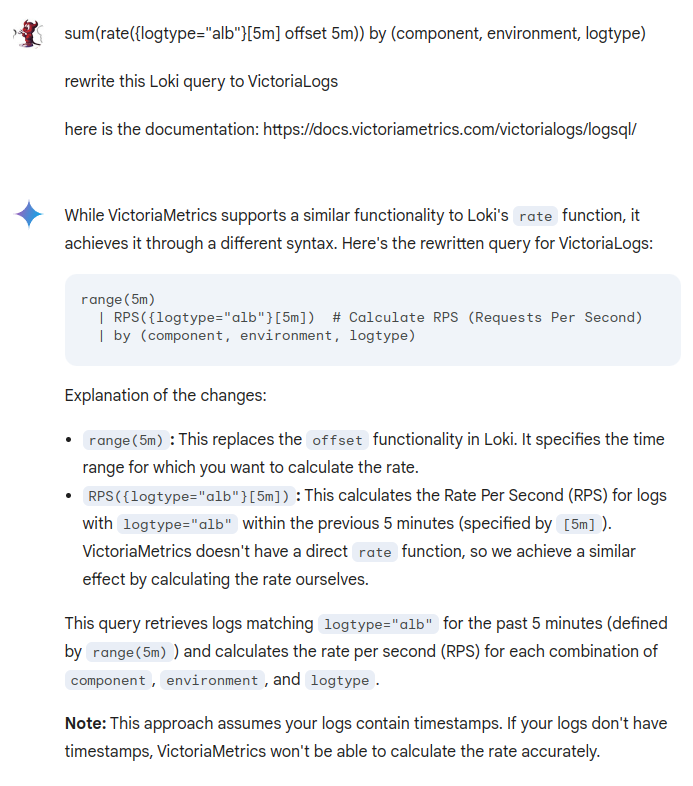
我尝试用一些 AI 聊天机器人将查询从 Loki LogQL 重写为 VictoriaMetrics LogsQL,但结果非常令人失望。
ChatGPT 确实在产生幻觉,并生成像 SELECT 这样的根本不存在的结果:

Gemini 稍微好一些,至少有或多或少的真实操作符,但仍然不是可以直接复制和使用的情况:
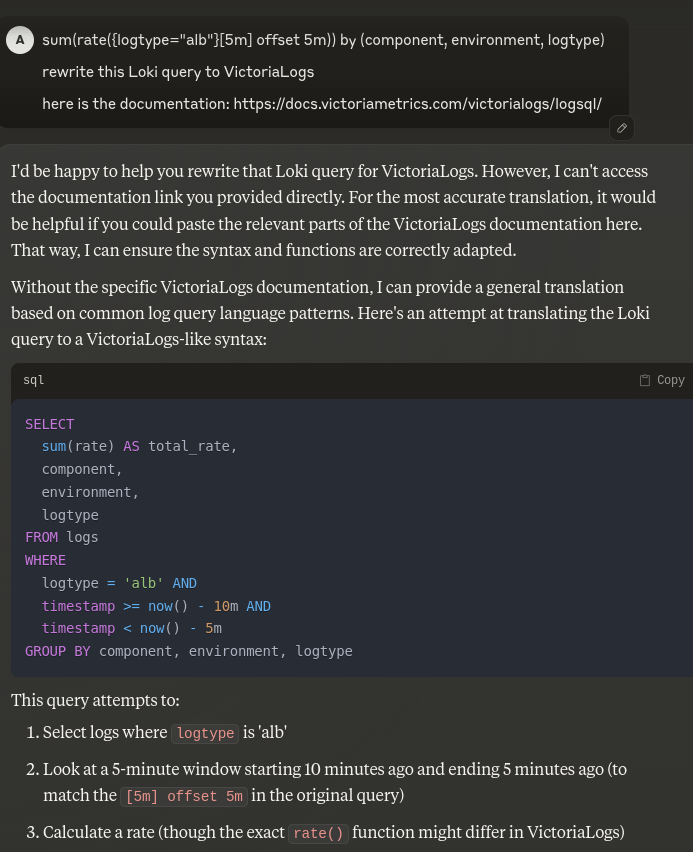
而 Claude 与 ChatGPT 类似,什么都不知道,但提供“类似的东西”:
但 Perplexity 几乎正确地回答了:
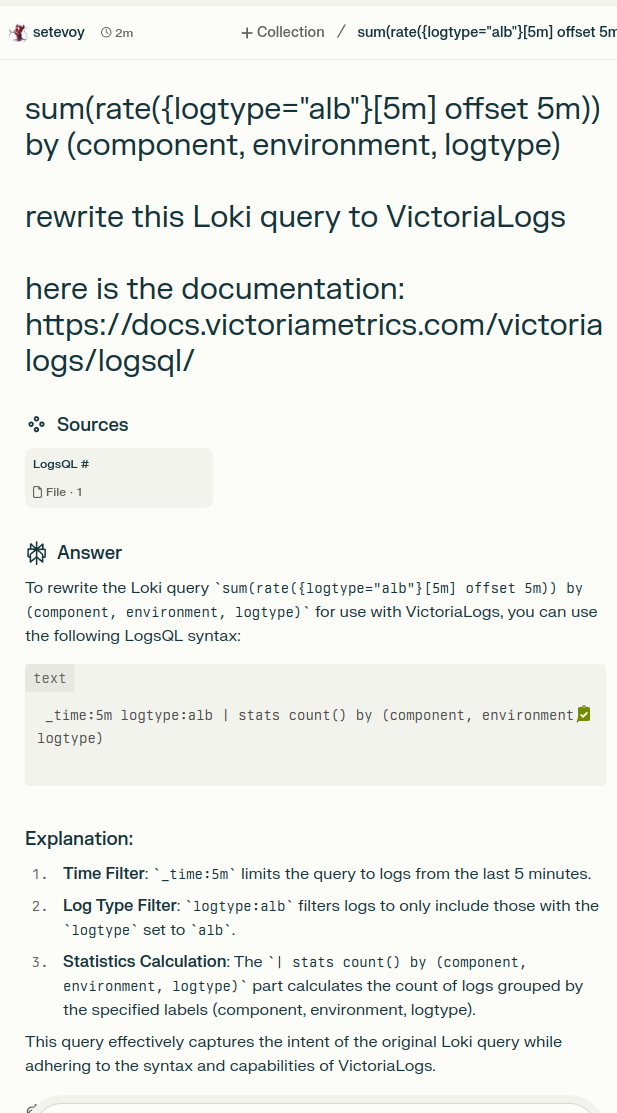
我刚刚把顺序弄错了—— by() 应该在 stats( ) 之后。
VictoriaLogs 子 Chart 安装
让我们用 Helm 添加 VictoriaLogs。
仅提醒您,在我当前的项目中,我们已经从我们自己的 chart 中安装了整个监控堆栈,其中 victoria-metrics-k8s-stack 、 k8s-event-logger 、 aws-xray 等是通过 Helm 依赖项添加的。
删除手动安装的图表:
$ helm -n ops-test-vmlogs-ns uninstall vlsingle
在 Chart.yaml 文件中,添加另一个 dependency :
apiVersion: v2
name: atlas-victoriametrics
description: A Helm chart for Atlas Victoria Metrics kubernetes monitoring stack
type: application
version: 0.1.1
appVersion: "1.17.0"
dependencies:
- name: victoria-metrics-k8s-stack
version: ~0.25.0
repository: https://victoriametrics.github.io/helm-charts
- name: victoria-metrics-auth
version: ~0.6.0
repository: https://victoriametrics.github.io/helm-charts
- name: victoria-logs-single
version: ~0.6.0
repository: https://victoriametrics.github.io/helm-charts
...
更新子 chart:
$ helm dependency build
更新我们的值 — 添加持久化存储:
...
victoria-logs-single:
server:
persistentVolume:
enabled: true
storageClassName: gp2-retain
size: 3Gi # default value, to update later
...
部署它并检查 VictoriaLogs 的服务名称:
$ kk get svc | grep logs
atlas-victoriametrics-victoria-logs-single-server ClusterIP None <none> 9428/TCP 2m32s
编辑 Promtail 配置 — 设置一个新的 URL:
...
promtail:
config:
clients:
- url: http://atlas-victoriametrics-loki-gateway/loki/api/v1/push
- url: http://atlas-victoriametrics-victoria-logs-single-server:9428/insert/loki/api/v1/push?_stream_fields=namespace
...
连接 Grafana 数据源
我不得不稍微调整一下 Grafana 的值,最终结果是这样的:
...
grafana:
enabled: true
env:
GF_PLUGINS_ALLOW_LOADING_UNSIGNED_PLUGINS: "victorialogs-datasource"
...
plugins:
- grafana-sentry-datasource
- grafana-clock-panel
- grafana-redshift-datasource
- https://github.com/VictoriaMetrics/victorialogs-datasource/releases/download/v0.4.0/victorialogs-datasource-v0.4.0.zip;victorialogs-datasource
additionalDataSources:
- name: Loki
type: loki
access: proxy
url: http://atlas-victoriametrics-loki-gateway:80
jsonData:
maxLines: 1000
timeout: 3m
- name: VictoriaLogs
type: victorialogs-datasource
access: proxy
url: http://atlas-victoriametrics-victoria-logs-single-server:9428
在发布页面可以查找版本,最新版本是 v0.4.0 。
请注意,URL 中两次指定了版本 — /releases/download/v0.4.0/victorialogs-datasource-v0.4.0.zip 。
部署它,如果需要,重启 Grafana Pods(除非你使用类似 Reloader 的工具),并检查数据源:
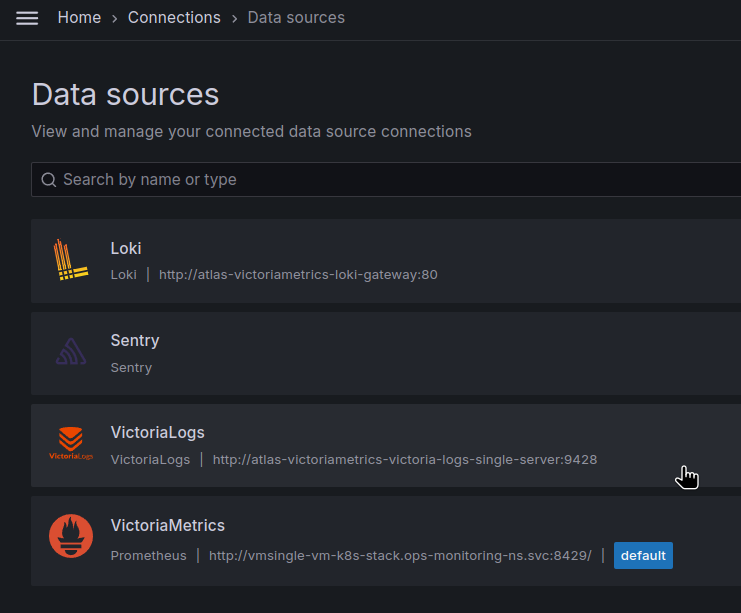
让我们用 Grafana Explore 试试:
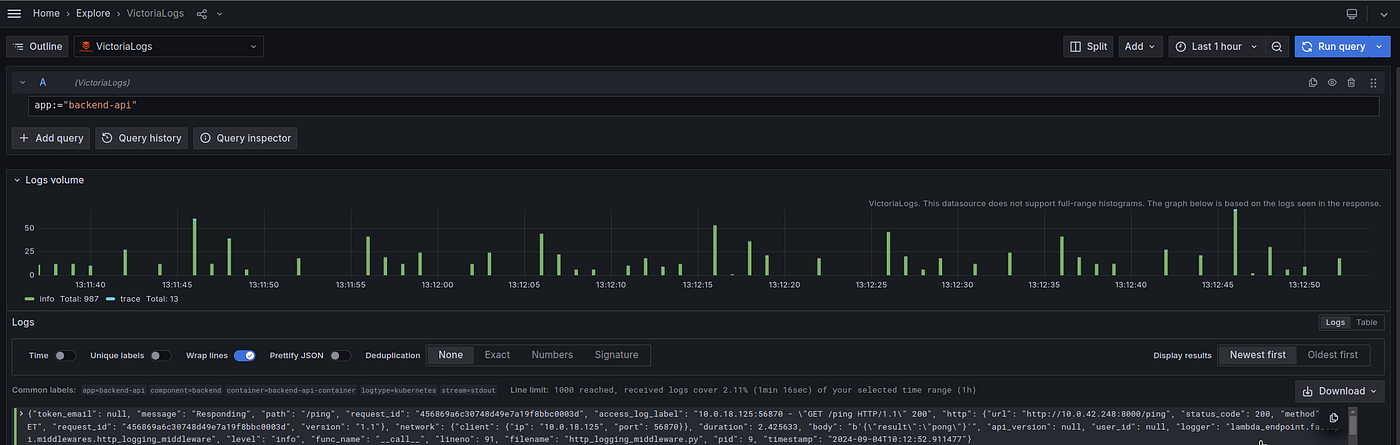
“它有效!”
Grafana 仪表板和时间序列可视化
在 Grafana 中的可视化还不完美,因为你需要添加转换才能使 Grafana 面板正确显示数据。
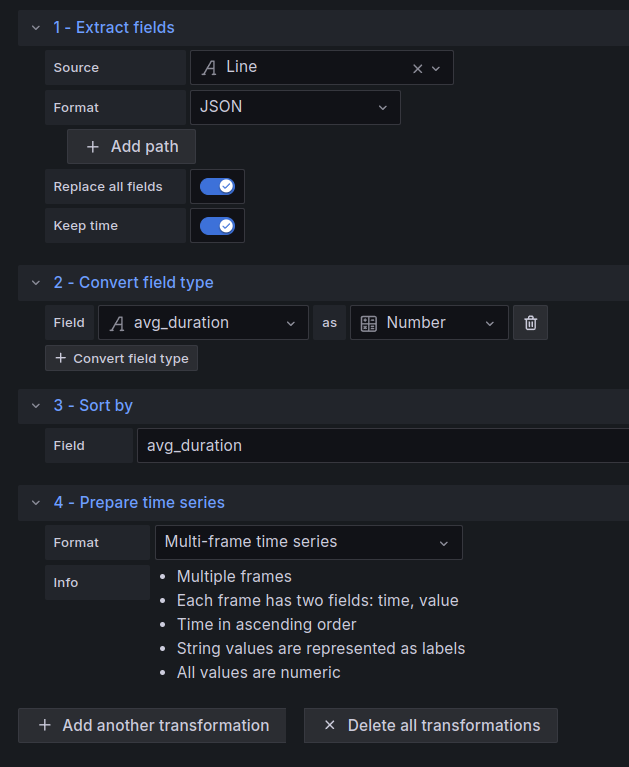
我必须至少添加其中四个:
- 提取字段:我们从 VictoriaLogs 中获取 JSON 格式的结果,通过此转换,我们从中提取所有字段
- 转换字段类型:JSON 中的
duration字段是字符串,因此需要将其更改为数字 - 排序方式:按
avg_duration字段排序 - 准备时间序列:将结果转换为时间序列可视化面板能够理解的格式
如果没有这个,您将会遇到诸如“数据缺少数字字段”、“数据缺少时间字段”或“数据超出时间范围”等错误。
配置转换:
图表的查询如下:
app:="backend-api" namespace:="prod-backend-api-ns" | unpack_json | keep path, duration, _msg, _time | path:!"" | stats by(_time:1m, path) avg(duration) avg_duration
请注意,这里 _time 已移至 stats() 调用,以获取每个 path 的最后一分钟统计数据。
结果如下:
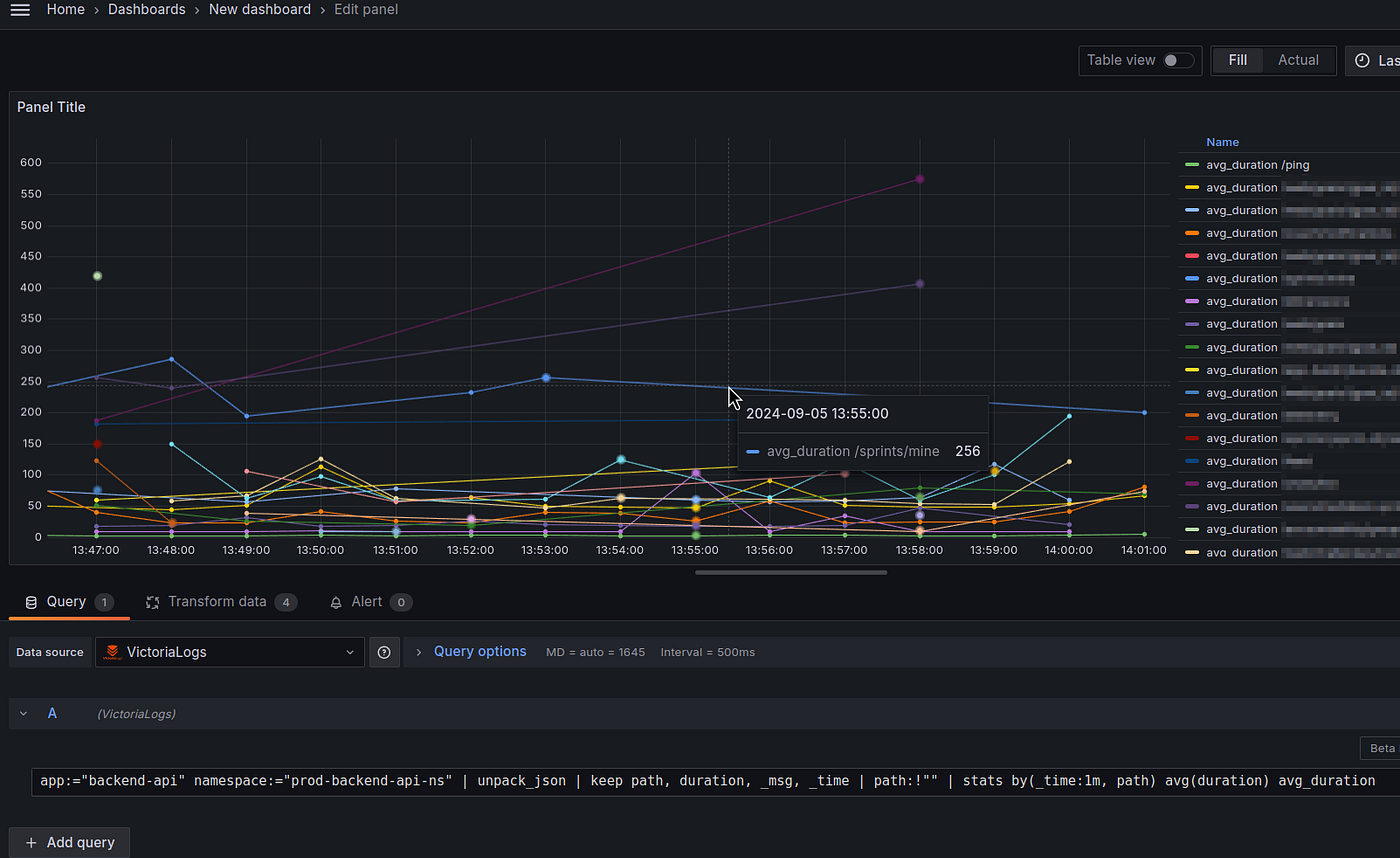
此外,数据源尚不允许您重写图例选项这些。
总结
要立即得出任何结论都很困难,但总体而言,我喜欢这个系统,绝对值得一试。
你需要习惯使用 LogSQL 并学习如何使用它,但它提供了更多的机会。
至于 CPU/内存资源,完全没有问题。
Grafana 数据源现在可以正常使用,不过我们可以等待其发布和添加更多功能。
我们也在等待添加对 AWS S3 的支持和 Loki RecordingRules,因为今天 VictoriaLogs 只能用作处理日志的系统,而不能用于图表或警报。
遗憾的是,ChatGPT 不能真正帮助处理 LogSQL 查询,因为我经常在 Loki 中使用它们。然而,Perplexity 几乎没有错误地响应。
所以,从好的方面来说:
- 它运行得非常快,并且确实使用了更少的资源
- LogSQL 功能丰富,非常不错
- VictoriaMetrics 文档总是相当详细,包含示例,结构良好
- VictoriaMetrics 的支持也很棒 — 在 GitHub Issues、Slack 和 Telegram 上 — 你总是可以提问并很快得到答案
- 与 Grafana Loki 不同,VictoriaLogs 有自己的 Web UI,对我来说,这是一个很大的优点
相对劣势:
- VictoriaLogs 及其 Grafana 数据源仍处于 Beta 阶段,因此可能会出现一些意外问题,并且尚未实现所有功能
- 但了解 VictoriaMetrics 团队,他们做事都很快
- 目前,缺乏 RecordingRules 和 AWS S3 支持是我个人无法完全移除 Grafana Loki 的原因
- 但所有主要功能应在 2024 年底前交付
- ChatGPT/Gemini/Claude 对 LogsSQL 了解不多,所以不要指望他们的帮助
- 但在 Slack 和 Telegram 上有来自 VictoriaMetrics 社区和开发团队的帮助,Perplexity 提供了足够好的结果
原文链接:https://rtfm.co.ua/en/victorialogs-an-overview-run-in-kubernetes-logsql-and-grafana/
阳明和他朋友们的一些项目




微信公众号
扫描下面的二维码关注我们的微信公众帐号,在微信公众帐号中回复◉加群◉即可加入到我们的 kubernetes 讨论群里面共同学习。
