对于生产环境以及一个有追求的运维人员来说,哪怕是毫秒级别的宕机也是不能容忍的。对基础设施及应用进行适当的日志记录和监控非常有助于解决问题,还可以帮助优化成本和资源,以及帮助检测以后可能会发生的一些问题。前面我们介绍了使用 EFK 技术栈来收集和监控日志,本文我们将使用更加轻量级的 Grafana Loki 来实现日志的监控和报警,一般来说 Grafana Loki 包括 3 个主要的组件:Promtail、Loki 和 Grafana(简称 PLG),最为关键的是如果你熟悉使用 Prometheus 的话,对于 Loki 的使用也完全没问题,因为他们的使用方法基本一致的,如果是在 Kubernetes 集群中自动发现的还具有相同的 Label 标签。
组件
在使用 Grafana Loki 之前,我们先简单介绍下他包含的 3 个主要组件。
Promtail
Promtail 是用来将容器日志发送到 Loki 或者 Grafana 服务上的日志收集工具,该工具主要包括发现采集目标以及给日志流添加上 Label 标签,然后发送给 Loki,另外 Promtail 的服务发现是基于 Prometheus 的服务发现机制实现的。
Loki
Loki 是一个受 Prometheus 启发的可以水平扩展、高可用以及支持多租户的日志聚合系统,使用了和 Prometheus 相同的服务发现机制,将标签添加到日志流中而不是构建全文索引。正因为如此,从 Promtail 接收到的日志和应用的 metrics 指标就具有相同的标签集。所以,它不仅提供了更好的日志和指标之间的上下文切换,还避免了对日志进行全文索引。
Grafana
Grafana 是一个用于监控和可视化观测的开源平台,支持非常丰富的数据源,在 Loki 技术栈中它专门用来展示来自 Prometheus 和 Loki 等数据源的时间序列数据。此外,还允许我们进行查询、可视化、报警等操作,可以用于创建、探索和共享数据 Dashboard,鼓励数据驱动的文化。
部署
为了方便部署 Loki 技术栈,我们这里使用更加方便的 Helm Chart 包进行安装,根据自己的需求修改对应的 Values 值。
首先我们先安装 Prometheus-Operator,因为该 Operator 里面就包含 Promtail、Prometheus、AlertManager 以及 Grafana,然后在单独安装 Loki 组件。
首先创建一个名为 loki-stack-values.yaml 的文件用于覆盖部署 Loki 的 Values 值,文件内容如下所示:
# Loki Stack Values
promtail:
serviceMonitor:
enabled: true
additionalLabels:
app: prometheus-operator
release: prometheus
pipelineStages:
- docker: {}
- match:
selector: '{app="nginx"}'
stages:
- regex:
expression: ".*(?P<hits>GET /.*)"
- metrics:
nginx_hits:
type: Counter
description: "Total nginx requests"
source: hits
config:
action: inc
这里我们为 Promtail 启用了 ServiceMonitor,并添加了两个标签。然后 Loki 对日志行进行转换,更改它的标签,并修改时间戳的格式。在这里我们添加了一个 match 的阶段,会去匹配具有 app=nginx 这样的日志流数据,然后下一个阶段是利用正则表达式过滤出包含 GET 关键字的日志行。
在 metrics 指标阶段,我们定义了一个 nginx_hits 的指标,Promtail 通过其 /metrics 端点暴露这个自定义的指标数据。这里我们定义的是一个 Counter 类型的指标,当从 regex 阶段被过滤后,这个计数器就会递增。为了在 Prometheus 中查看这个指标,我们需要抓取 Promtail 的这个指标。
使用如下所示的命令安装 Loki:
$ helm repo add loki https://grafana.github.io/loki/charts
$ helm repo update
$ helm upgrade --install loki loki/loki-stack --values=loki-stack-values.yaml -n kube-mon
然后安装 Prometheus Operator,同样创建一个名为 prom-oper-values.yaml 的文件,用来覆盖默认的 Values 值,文件内容如下所示:
grafana:
additionalDataSources:
- name: loki
access: proxy
orgId: 1
type: loki
url: http://loki:3100
version: 1
additionalPrometheusRules:
- name: loki-alert
groups:
- name: test_nginx_logs
rules:
- alert: nginx_hits
expr: sum(increase(promtail_custom_nginx_hits[1m])) > 2
for: 2m
annotations:
message: "nginx_hits total insufficient count ({{ $value }})."
alertmanager:
config:
global:
resolve_timeout: 1m
route:
group_by: ["alertname"]
group_wait: 3s
group_interval: 5s
repeat_interval: 1m
receiver: webhook-alert
routes:
- match:
alertname: nginx_hits
receiver: webhook-alert
receivers:
- name: "webhook-alert"
webhook_configs:
- url: "http://dingtalk-hook:5000"
send_resolved: true
这里我们为 Grafana 配置了 Loki 这个数据源,然后配置了名为 nginx_hits 的报警规则,这些规则在同一个分组中,每隔一定的时间间隔依次执行。触发报警的阈值通过 expr 表达式进行配置。我们这里表示的是 1 分钟之内新增的总和是否大于 2,当 expor 表达式的条件持续了 2 分钟时间后,报警就会真正被触发,报警真正被触发之前会保持为 Pending 状态。
最后我们配置 Alertmanager 通过 WebHook 来发送通知,Alertmanager 根据树状结构来路由传入的告警信息。我们可以根据 alertname、job、cluster 等对报警进行分组。当告警信息匹配时,就会在预设的接收器上发送通知。
安装命令如下所示:
$ helm upgrade --install prometheus stable/prometheus-operator --values=prom-oper-values.yaml -n kube-mon
接下来我们可以安装一个测试使用的 Nginx 应用,对应的资源清单如下所示:(nginx-deploy.yaml)
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
selector:
matchLabels:
app: nginx
replicas: 1
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
jobLabel: nginx
spec:
ports:
- name: nginx
port: 80
protocol: TCP
selector:
app: nginx
type: NodePort
为方便测试,我们这里使用 NodePort 类型的服务来暴露应用,直接安装即可:
$ kubectl apply -f nginx-deploy.yaml
所有应用安装完成后的 Pod 列表如下所示:
$ kubectl get pods -n kube-mon
NAME READY STATUS RESTARTS AGE
alertmanager-prometheus-prometheus-oper-alertmanager-0 2/2 Running 0 6m16s
loki-0 1/1 Running 0 39m
loki-promtail-62thc 1/1 Running 0 17m
loki-promtail-99bpf 1/1 Running 0 17m
loki-promtail-ljw5m 1/1 Running 0 17m
loki-promtail-mr85p 1/1 Running 0 17m
loki-promtail-pw896 1/1 Running 0 17m
loki-promtail-vq8rl 1/1 Running 0 17m
prometheus-grafana-76668d6c47-xf8d7 2/2 Running 0 13m
prometheus-kube-state-metrics-7c64748dd4-5fhns 1/1 Running 0 13m
prometheus-prometheus-oper-admission-patch-pkkp9 0/1 Completed 0 8m7s
prometheus-prometheus-oper-operator-765447bc5-vcdzs 2/2 Running 0 13m
prometheus-prometheus-prometheus-oper-prometheus-0 3/3 Running 1 6m17s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-6f8b869ccf-58rzx 1/1 Running 0 16s
为方便测试,我们可以将 Prometheus Operator 安装的 Grafana 对应的 Service 改成 NodePort 类型,然后用默认的 admin 用户名和密码 prom-operator 可以登录到 Grafana。
测试
这里我们来模拟触发告警,通过如下所示的 shell 命令来模拟每隔 10s 访问 Nginx 应用。
$ while true; do curl --silent --output /dev/null --write-out '%{http_code}' http://k8s.qikqiak.com:31940; sleep 10; echo; done
200
200
这个时候我们去 Grafana 页面筛选 Nginx 应用的日志就可以看到了:
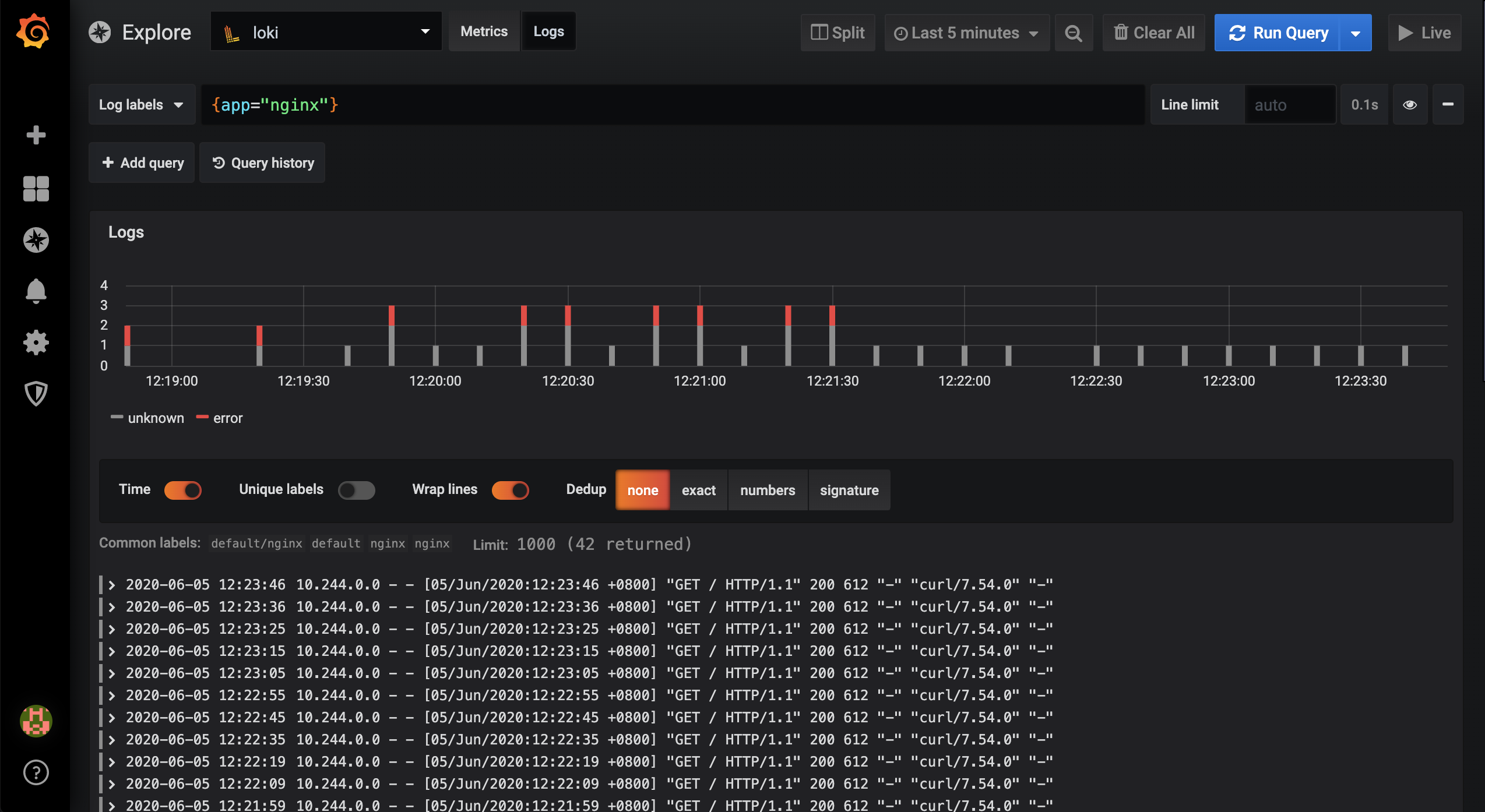
同时这个时候我们配置的 nginx-hints 报警规则也被触发了:
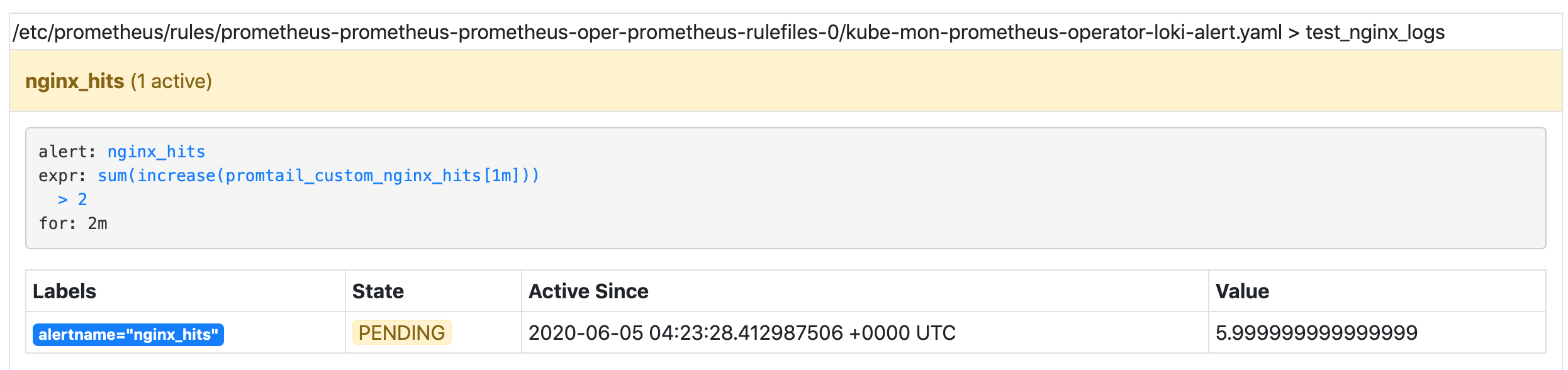
如果在两分钟之内报警阈值一直达到,则会触发报警:
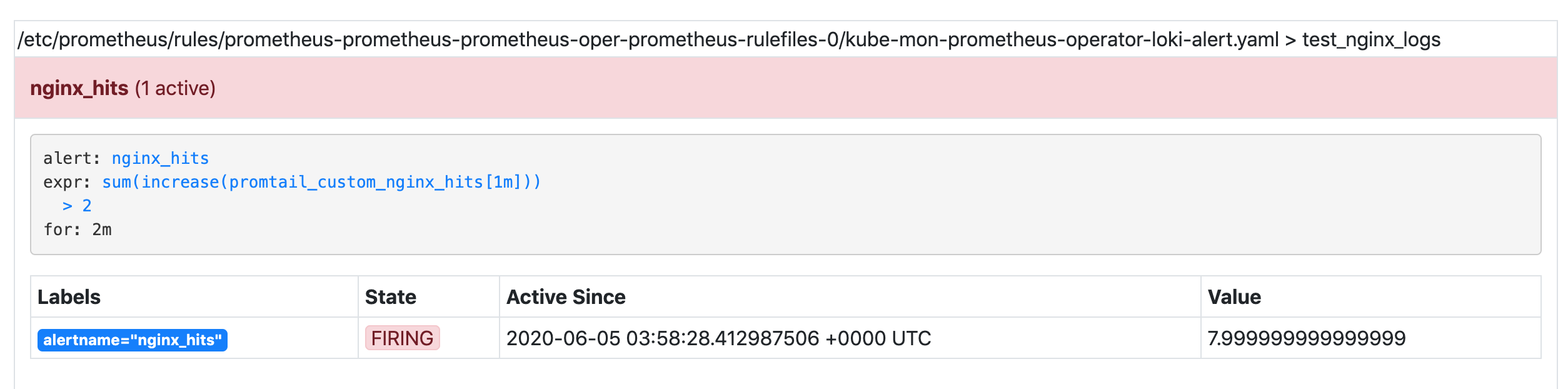
正常这个时候我们的 WebHook 中也可以收到对应的报警信息了。
到这里我们就完成了使用 PLG 技术栈来对应用进行日志收集、监控和报警的操作。
参考链接
- https://github.com/grafana/loki/tree/master/docs
- https://www.infracloud.io/grafana-loki-log-monitoring-alerting/
阳明和他朋友们的一些项目




微信公众号
扫描下面的二维码关注我们的微信公众帐号,在微信公众帐号中回复◉加群◉即可加入到我们的 kubernetes 讨论群里面共同学习。
