Prometheus 团队在 PromCon 大会上宣布了 Prometheus 3.0 版本的发布,并在官方博客上详细介绍了所有令人兴奋的新变化和功能。Prometheus 3.0 最引人注目的亮点之一是默认启用的全新 Web UI。
继续阅读 →标签: #Prometheus
我们了解了 Prometheus 的使用,了解了基本的 PromQL 语句以及结合 Grafana 来进行监控图表展示,通过 Alertmanager 来进行报警,这些工具结合起来已经可以帮助我们搭建一套比较完整的监控报警系统了,使用 Kube Prometheus 还可以搭建一站式的 Kubernetes 集群监控体系,但是对于生产环境来说则还有许多需要改进的地方。
单台的 Prometheus 存在单点故障的风险,随着监控规模的扩大,Prometheus 产生的数据量也会非常大,性能和存储都会面临问题。毋庸置疑,我们需要一套高可用的高性能的 Prometheus 集群。
继续阅读 →昨天在 Prometheus 课程辅导群里面有同学提到一个问题,是关于 Prometheus 监控 Job 任务误报的问题,大概的意思就 CronJob 控制的 Job,前面执行失败了,监控会触发报警,解决后后面生成的新的 Job 可以正常执行了,但是还是会收到前面的报警:
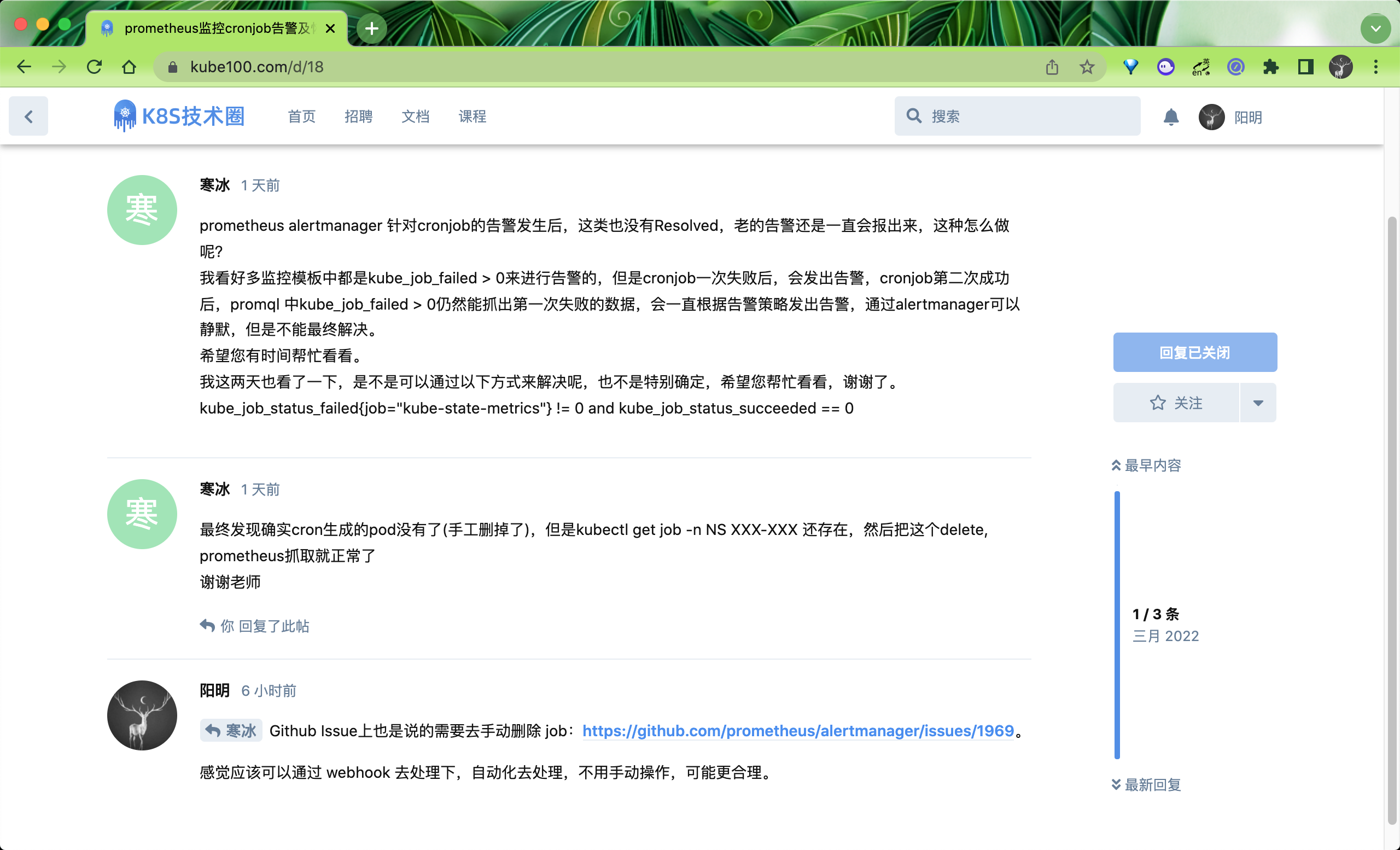
这是因为一般在执行 Job 任务的时候我们会保留一些历史记录方便排查问题,所以如果之前有失败的 Job 了,即便稍后会变成成功的,那么之前的 Job 也会继续存在,而大部分直接使用 kube-prometheus 安装部署的话使用的默认报警规则是kube_job_status_failed > 0,这显然是不准确的,只有我们去手动删除之前这个失败的 Job 任务才可以消除误报,当然这种方式是可以解决问题的,但是不够自动化,一开始没有想得很深入,想去自动化删除失败的 Job 来解决,但是这也会给运维人员带来问题,就是不方便回头去排查问题。下面我们来重新整理下思路解决下这个问题。
前面我们的文章中都是将 Prometheus 安装在 Kubernetes 集群中来采集数据,但是在实际环境中很多企业是将 Prometheus 单独部署在集群外部的,甚至直接监控多个 Kubernetes 集群,虽然不推荐这样去做,因为 Prometheus 采集的数据量太大,或大量消耗资源,比较推荐的做法是用不同的 Prometheus 实例监控不同的集群,然后用联邦的方式进行汇总。但是使用 Prometheus 监控外部的 Kubernetes 集群这个需求还是非常有必要的。
继续阅读 →对于生产环境以及一个有追求的运维人员来说,哪怕是毫秒级别的宕机也是不能容忍的。对基础设施及应用进行适当的日志记录和监控非常有助于解决问题,还可以帮助优化成本和资源,以及帮助检测以后可能会发生的一些问题。前面我们介绍了使用 EFK 技术栈来收集和监控日志,本文我们将使用更加轻量级的 Grafana Loki 来实现日志的监控和报警,一般来说 Grafana Loki 包括 3 个主要的组件:Promtail、Loki 和 Grafana(简称 PLG),最为关键的是如果你熟悉使用 Prometheus 的话,对于 Loki 的使用也完全没问题,因为他们的使用方法基本一致的,如果是在 Kubernetes 集群中自动发现的还具有相同的 Label 标签。
继续阅读 →在前面的学习中我们使用用一个 kubectl scale 命令可以来实现 Pod 的扩缩容功能,但是这个毕竟是完全手动操作的,要应对线上的各种复杂情况,我们需要能够做到自动化去感知业务,来自动进行扩缩容。为此,Kubernetes 也为我们提供了这样的一个资源对象:Horizontal Pod Autoscaling(Pod 水平自动伸缩),简称HPA,HPA 通过监控分析一些控制器控制的所有 Pod 的负载变化情况来确定是否需要调整 Pod 的副本数量,这是 HPA 最基本的原理:

我们可以简单的通过 kubectl autoscale 命令来创建一个 HPA 资源对象,HPA Controller默认30s轮询一次(可通过 kube-controller-manager 的--horizontal-pod-autoscaler-sync-period 参数进行设置),查询指定的资源中的 Pod 资源使用率,并且与创建时设定的值和指标做对比,从而实现自动伸缩的功能。
我们在使用 Grafana Dashboard 来展示我们的监控图表的时候,很多时候我们都是去找别人已经做好的 Dashboard 拿过来改一改,但是这样也造成了很多使用 Grafana 的人员压根不知道如何去自定义一个 Dashboard,虽然这并不是很困难。这里我们介绍一个比较新颖(骚)的工具:DARK,全称 Dashboards As Resources in Kubernetes.,意思就是通过 Kubernetes 的资源对象来定义 Grafana Dashboard,实现原理也很简单,也就是通过 CRD 来定义 Dashboard,然后通过和 Grafana 的 API Token 进行交互实现 Dashboard 的 CRUD。
在使用 Prometheus 进行监控的时候,通过 AlertManager 来进行告警,但是有很多人对报警的相关配置比较迷糊,不太清楚具体什么时候会进行告警。下面我们来简单介绍下 AlertManager 中的几个容易混淆的参数。
继续阅读 →DevOpsProdigy KubeGraf 是一个非常优秀的 Grafana Kubernetes 插件,是 Grafana 官方的 Kubernetes 插件 的升级版本,该插件可以用来可视化和分析 Kubernetes 集群的性能,通过各种图形直观的展示了 Kubernetes 集群的主要服务的指标和特征,还可以用于检查应用程序的生命周期和错误日志。
继续阅读 →Prometheus 作为现在最火的云原生监控工具,它的优秀表现是毋庸置疑的。但是在我们使用过程中,随着时间的推移,存储在 Prometheus 中的监控指标数据越来越多,查询的频率也在不断的增加,当我们用 Grafana 添加更多的 Dashboard 的时候,可能慢慢地会体验到 Grafana 已经无法按时渲染图表,并且偶尔还会出现超时的情况,特别是当我们在长时间汇总大量的指标数据的时候,Prometheus 查询超时的情况可能更多了,这时就需要一种能够类似于后台批处理的机制在后台完成这些复杂运算的计算,对于使用者而言只需要查询这些运算结果即可。Prometheus 提供一种记录规则(Recording Rule) 来支持这种后台计算的方式,可以实现对复杂查询的 PromQL 语句的性能优化,提高查询效率。
继续阅读 →前面我们主要介绍了 Prometheus 下如何进行白盒监控,我们监控主机的资源用量、容器的运行状态、数据库中间件的运行数据、自动发现 Kubernetes 集群中的资源等等,这些都是支持业务和服务的基础设施,通过白盒能够了解其内部的实际运行状态,通过对监控指标的观察能够预判可能出现的问题,从而对潜在的不确定因素进行优化。而从完整的监控逻辑的角度,除了大量的应用白盒监控以外,还应该添加适当的 Blackbox(黑盒)监控,黑盒监控即以用户的身份测试服务的外部可见性,常见的黑盒监控包括HTTP 探针、TCP 探针 等用于检测站点或者服务的可访问性,以及访问效率等。
黑盒监控相较于白盒监控最大的不同在于黑盒监控是以故障为导向当故障发生时,黑盒监控能快速发现故障,而白盒监控则侧重于主动发现或者预测潜在的问题。一个完善的监控目标是要能够从白盒的角度发现潜在问题,能够在黑盒的角度快速发现已经发生的问题。
Blackbox Exporter 是 Prometheus 社区提供的官方黑盒监控解决方案,其允许用户通过:HTTP、HTTPS、DNS、TCP 以及 ICMP 的方式对网络进行探测。
前面我们学习了很多关于 Prometheus 的内容,也学习了 HPA 对象的使用,但是一直没有对自定义指标来对应用进行扩缩容做过讲解,本篇文章我们就来了解下如何通过自定义指标来做应用的动态伸缩功能。当前前提是你需要熟悉 Kubernetes 和 Prometheus,如果不熟悉的话可以查看我们前面的一系列文章,或者直接查看我们的 Kubernetes 进阶视频课程。
继续阅读 →