千呼万唤始出来,国内第一本全方位讲解Prometheus的书籍《深入浅出Prometheus》终于出版了,非常荣幸能和陈晓宇、陈啸两位老师参与本书的编写,这也是我参与的第一本严格意义上的书籍,另外两位老师对于Prometheus研究的深度让我非常佩服,在编写本书的过程中也学习到了很多专业的知识,特别是关于Prometheus原理和源码方面的认识,之前都只是局限于应用层面,在了解了原理过后显然可以让我们更加有信心去使用Prometheus。
标签: #Prometheus
 使用
使用Helm可以很方便的部署 Kubernetes 应用,但是如果对于线上的应用部署或者更新后出现了问题,要及时回滚到之前的版本该如何去做呢?当然我们可以手动通过kubectl rollout去进行控制,但是难免需要手动去操作。今天给大家介绍一个 Helm 的插件 Helm monitro,通过监听 Prometheus 或 ElasticSearch 监控或者日志数据,在发生故障时自动回滚 release。
有的时候我们可能希望从 Prometheus 中删除一些不需要的数据指标,或者只是单纯的想要释放一些磁盘空间。Prometheus 中的时间序列只能通过 HTTP API 来进行管理。
继续阅读 → 上节课我们一起学习了如何在 Prometheus Operator 下面自定义一个监控选项,以及自定义报警规则的使用。那么我们还能够直接使用前面课程中的自动发现功能吗?如果在我们的 Kubernetes 集群中有了很多的 Service/Pod,那么我们都需要一个一个的去建立一个对应的 ServiceMonitor 对象来进行监控吗?这样岂不是又变得麻烦起来了?
上节课我们一起学习了如何在 Prometheus Operator 下面自定义一个监控选项,以及自定义报警规则的使用。那么我们还能够直接使用前面课程中的自动发现功能吗?如果在我们的 Kubernetes 集群中有了很多的 Service/Pod,那么我们都需要一个一个的去建立一个对应的 ServiceMonitor 对象来进行监控吗?这样岂不是又变得麻烦起来了?
上篇文章我们介绍了如何自定义一个 ServiceMonitor 对象,但是如果需要自定义一个报警规则的话呢?又该怎么去做呢?
继续阅读 →上节课和大家讲解了 Prometheus Operator 的安装和基本使用方法,这节课给大家介绍如何在 Prometheus Operator 中添加一个自定义的监控项。
除了 Kubernetes 集群中的一些资源对象、节点以及组件需要监控,有的时候我们可能还需要根据实际的业务需求去添加自定义的监控项,添加一个自定义监控的步骤也是非常简单的。
- 第一步建立一个 ServiceMonitor 对象,用于 Prometheus 添加监控项
- 第二步为 ServiceMonitor 对象关联 metrics 数据接口的一个 Service 对象
- 第三步确保 Service 对象可以正确获取到 metrics 数据
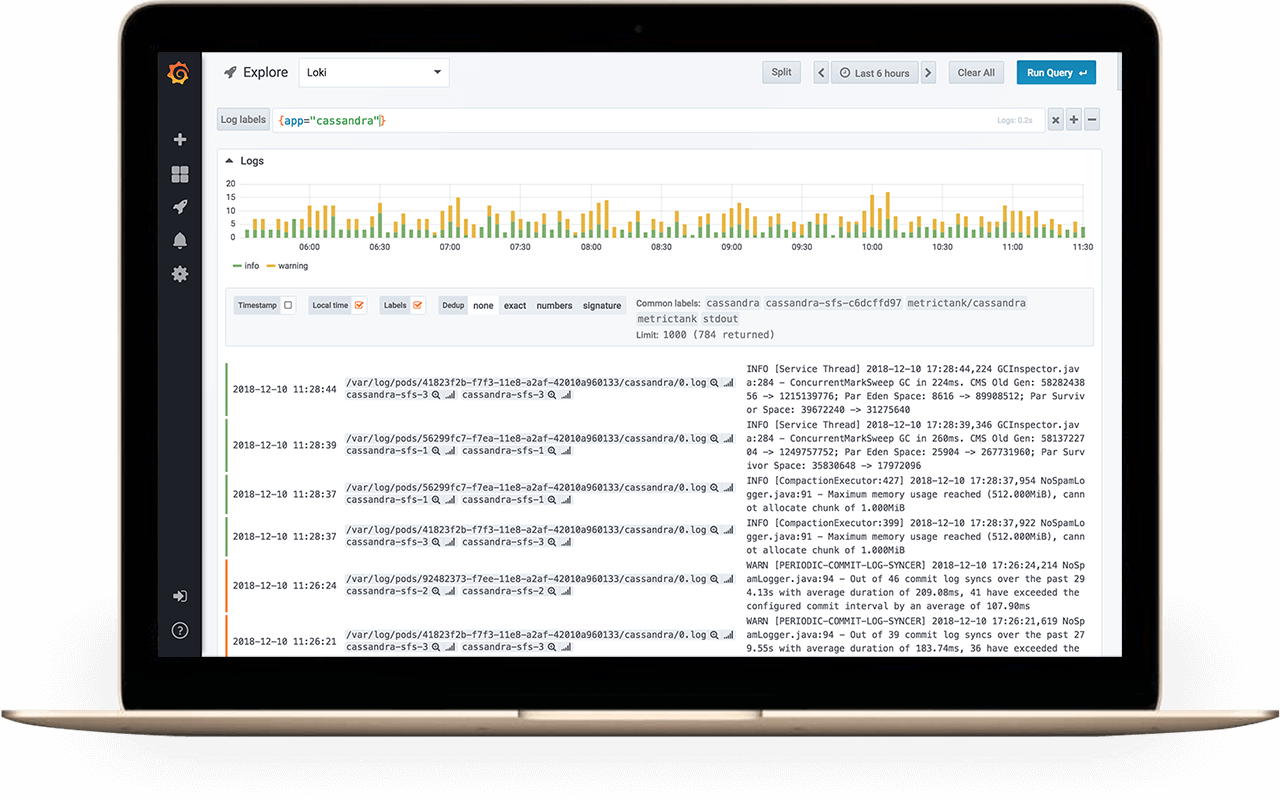
Loki是 Grafana Labs 团队最新的开源项目,是一个水平可扩展,高可用性,多租户的日志聚合系统。它的设计非常经济高效且易于操作,因为它不会为日志内容编制索引,而是为每个日志流编制一组标签。项目受 Prometheus 启发,官方的介绍就是:Like Prometheus, but for logs.,类似于 Prometheus 的日志系统。
前面的课程中我们学习了用自定义的方式来对 Kubernetes 集群进行监控,但是还是有一些缺陷,比如 Prometheus、AlertManager 这些组件服务本身的高可用,当然我们也完全可以用自定义的方式来实现这些需求,我们也知道 Prometheus 在代码上就已经对 Kubernetes 有了原生的支持,可以通过服务发现的形式来自动监控集群,因此我们可以使用另外一种更加高级的方式来部署 Prometheus:Operator 框架。
 前面的课程中我们使用 Prometheus 采集了 Kubernetes 集群中的一些监控数据指标,我们也尝试使用
前面的课程中我们使用 Prometheus 采集了 Kubernetes 集群中的一些监控数据指标,我们也尝试使用promQL语句查询出了一些数据,并且在 Prometheus 的 Dashboard 中进行了展示,但是明显可以感觉到 Prometheus 的图表功能相对较弱,所以一般情况下我们会一个第三方的工具来展示这些数据,今天我们要和大家使用到的就是grafana。
 上节课我们和大家学习了怎样用 Promethues 来监控 Kubernetes 集群中的应用,但是对于 Kubernetes 集群本身的监控也是非常重要的,我们需要时时刻刻了解集群的运行状态。
上节课我们和大家学习了怎样用 Promethues 来监控 Kubernetes 集群中的应用,但是对于 Kubernetes 集群本身的监控也是非常重要的,我们需要时时刻刻了解集群的运行状态。
对于集群的监控一般我们需要考虑以下几个方面:
- Kubernetes 节点的监控:比如节点的 cpu、load、disk、memory 等指标
- 内部系统组件的状态:比如 kube-scheduler、kube-controller-manager、kubedns/coredns 等组件的详细运行状态
- 编排级的 metrics:比如 Deployment 的状态、资源请求、调度和 API 延迟等数据指标

在前面一文Kubernetes使用Prometheus搭建监控平台中我们知道了怎么使用Prometheus来搭建监控平台,也了解了grafana的使用。这篇文章就来说说报警系统的搭建,有人说报警用grafana就行了,实际上grafana对报警的支持真的很弱,而Prometheus提供的报警系统就强大很多,今天我们的主角就是AlertManager。