最近,一个国产开源项目凭借高质量的代码、飞快的迭代速度和简洁友好的操作体验正在悄然崛起。短短半年内,这个项目已经在国内外开源社区获得了众多的拥趸和生产用户。它就是今天要介绍的开源项目 - GPUStack。

GPUStack 是一个 100% 开源的大模型服务平台,用户只需要简单的设置,就可以高效整合包括 NVIDIA、Apple Metal、华为昇腾和摩尔线程在内的各种异构 GPU/NPU 资源,构建异构 GPU 集群,在私有环境提供企业级的大模型部署解决方案。
GPUStack 支持私有化部署 RAG 系统和 AI Agent 系统所需的各种关键模型,包括 LLM 大语言模型、VLM 多模态模型、Embedding 文本嵌入模型、Rerank 重排序模型、Text-to-Image 文生图模型,以及 Speech-to-Text(STT)和 Text-to-Speech(TTS)语音模型等。并提供统一认证和高可用负载均衡的 OpenAI 兼容 API,供用户从各类大模型云服务无缝迁移到本地部署的私有大模型服务。
GPUStack 介绍
GPUStack 是一个集群化和自动化的大模型部署解决方案,用户不需要手动管理多台 GPU 节点和手动协调分配资源,通过 GPUStack 内置的紧凑调度、分散调度、指定 Worker 标签调度、指定 GPU 调度等各种调度策略,用户无需手动干预即可自动分配合适的 GPU 资源来运行大模型。
对于无法在单个 GPU 节点运行的大参数量模型,GPUStack 提供分布式推理功能,可以自动将模型运行在跨主机的多个 GPU 上。同时,在实验环境中,用户还可以采用 GPU&CPU 混合推理或纯 CPU 推理模式,利用 CPU 算力来运行大模型,提供更广泛的兼容性和灵活性。
GPUStack 具有以下特点:
- 多平台和异构 GPU 支持
GPUStack 支持 amd64 和 arm64 架构的 Linux、Windows 和 macOS 平台,可以纳管 NVIDIA、Apple Metal、华为昇腾和摩尔线程等各种类型的 GPU/NPU。
- 多推理引擎和多版本支持
GPUStack 支持 vLLM、**llama-box(基于 llama.cpp 与 stable-diffusion.cpp )**和 vox-box 推理引擎,满足不同场景下的大模型部署需求。
vLLM 是面向生产环境的高性能推理引擎,专为高并发和高吞吐量场景优化,广泛应用于数据中心场景,但仅支持 Linux 系统,适用于对性能有要求的应用场景。
llama-box 是 GPUStack 推出的推理引擎,基于 llama.cpp 与 stable-diffusion.cpp,提供对 LLM 大语言模型、VLM 多模态模型、Embedding 文本嵌入模型、Rerank 重排序模型、Text-to-Image 文生图模型的支持。
llama-box 是一个灵活、兼容多平台的推理引擎,兼容 Linux、Windows 和 macOS,支持在 NVIDIA、Apple Metal、华为昇腾和摩尔线程等各种 GPU/NPU 环境以及 CPU 环境运行模型,它的灵活性和兼容性使其成为资源有限场景(如 AI PC 和 Edge)的理想选择。
vox-box 是 GPUStack 提供的专注于语音模型的推理引擎,支持 **Text-to-Speech(TTS)**和 **Speech-to-Text(STT)**模型,并提供 OpenAI 兼容 API。目前对接了 Whisper、FunASR、Bark 和 CosyVoice 后端,支持运行 Whisper、Paraformer、Conformer、SenseVoice 等 STT 模型,以及 Bark 和 CosyVoice 等 TTS 模型。
GPUStack 还提供推理引擎的版本管理能力。用户可以在部署模型时,为每个模型固定任意可用的推理引擎版本。运维人员可以灵活使用多个推理引擎版本来满足新旧模型的兼容需求,在引入新模型的同时保证旧模型的稳定运行。
- 多模型类型支持
GPUStack 支持 LLM 大语言模型、VLM 多模态模型、Embedding 文本嵌入模型、Rerank 重排序模型、Text-to-Image 文生图模型、Speech-to-Text(STT)和 Text-to-Speech(TTS)语音模型等各种模型,用户可以选择从 Hugging Face、ModelScope、Ollama Library、私有模型仓库或本地路径部署这些模型。
- 大语言模型
GPUStack 可以在 NVIDIA、Apple Metal、华为昇腾和摩尔线程等各种 GPU / NPU 上运行 LLM。同时支持 vLLM 和 llama-box 后端使得 GPUStack 可以全面地覆盖从实验室研发测试场景到生产应用落地场景,从数据中心、云到桌面、边缘的各种环境。
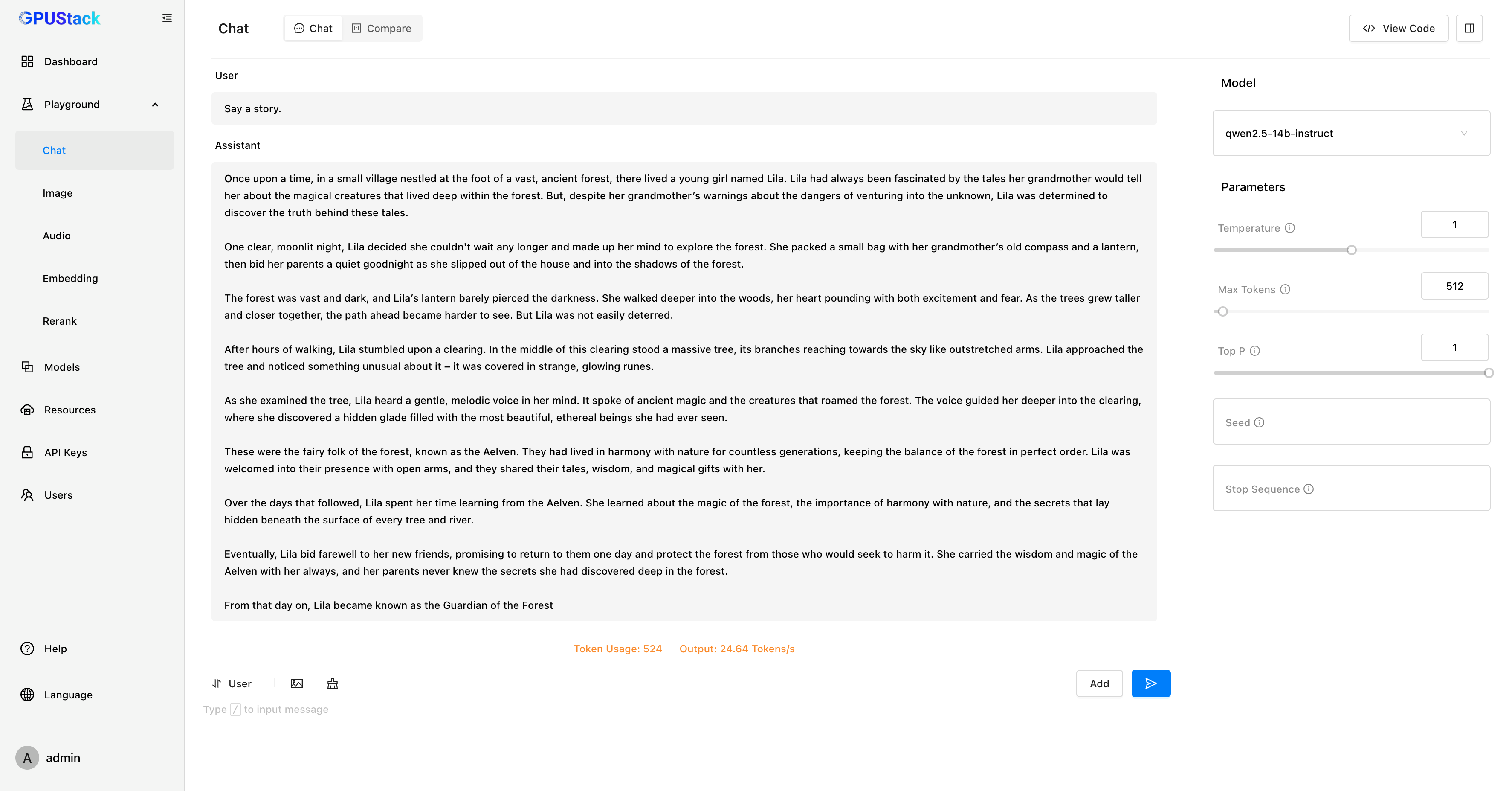
GPUStack 在 Playground 中提供了模型调测的能力,还支持多模型对比视图,可以同时对比多个模型的问答内容和性能数据,以评估不同模型、不同权重、不同 Prompt 参数、不同量化、不同 GPU、不同推理后端的模型推理表现。
如果需要跟 RAG 系统或 AI Agent 系统集成,GPUStack 提供了 OpenAI 兼容的 API,可以通过 View Code 查看动态生成的 API 调用代码示例。
- 多模态模型
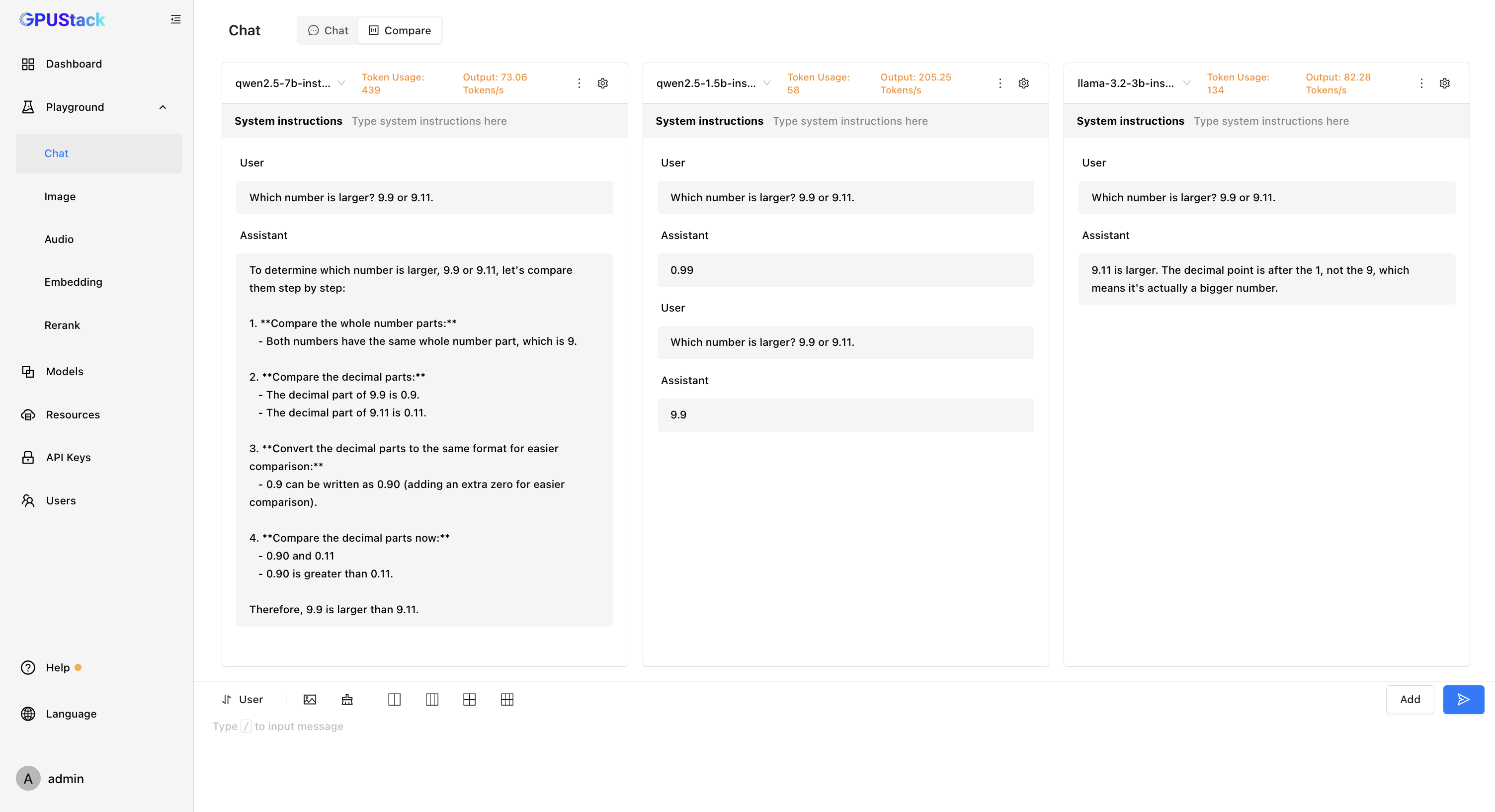
GPUStack 可以部署各种多模态模型,例如 Llama3.2-Vision、Pixtral、Qwen2-VL、LLaVA、InternVL2 等等,用于图像识别等任务,在 Playground 试验场中可以调测模型验证效果。
- Embedding 文本嵌入模型
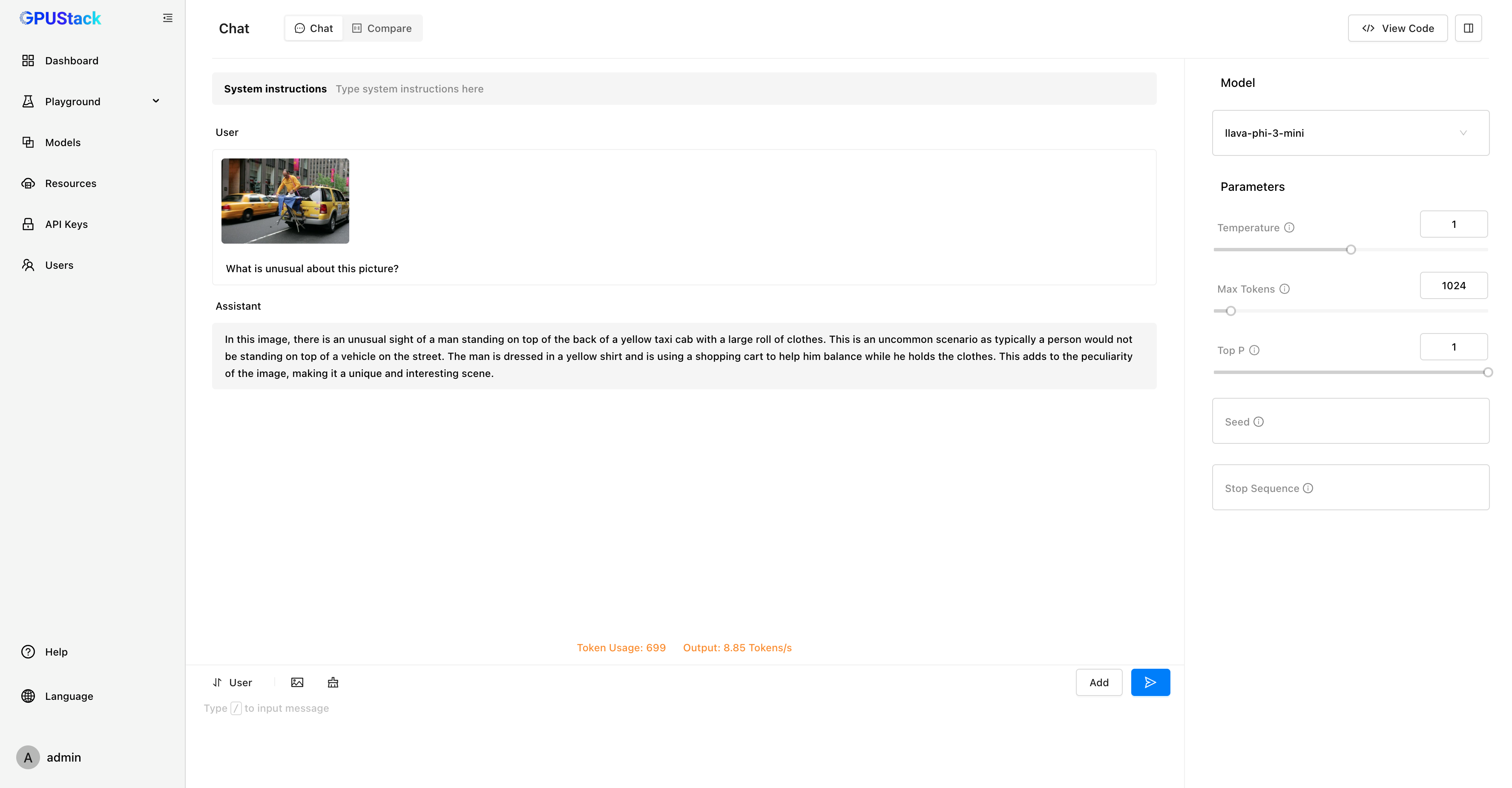
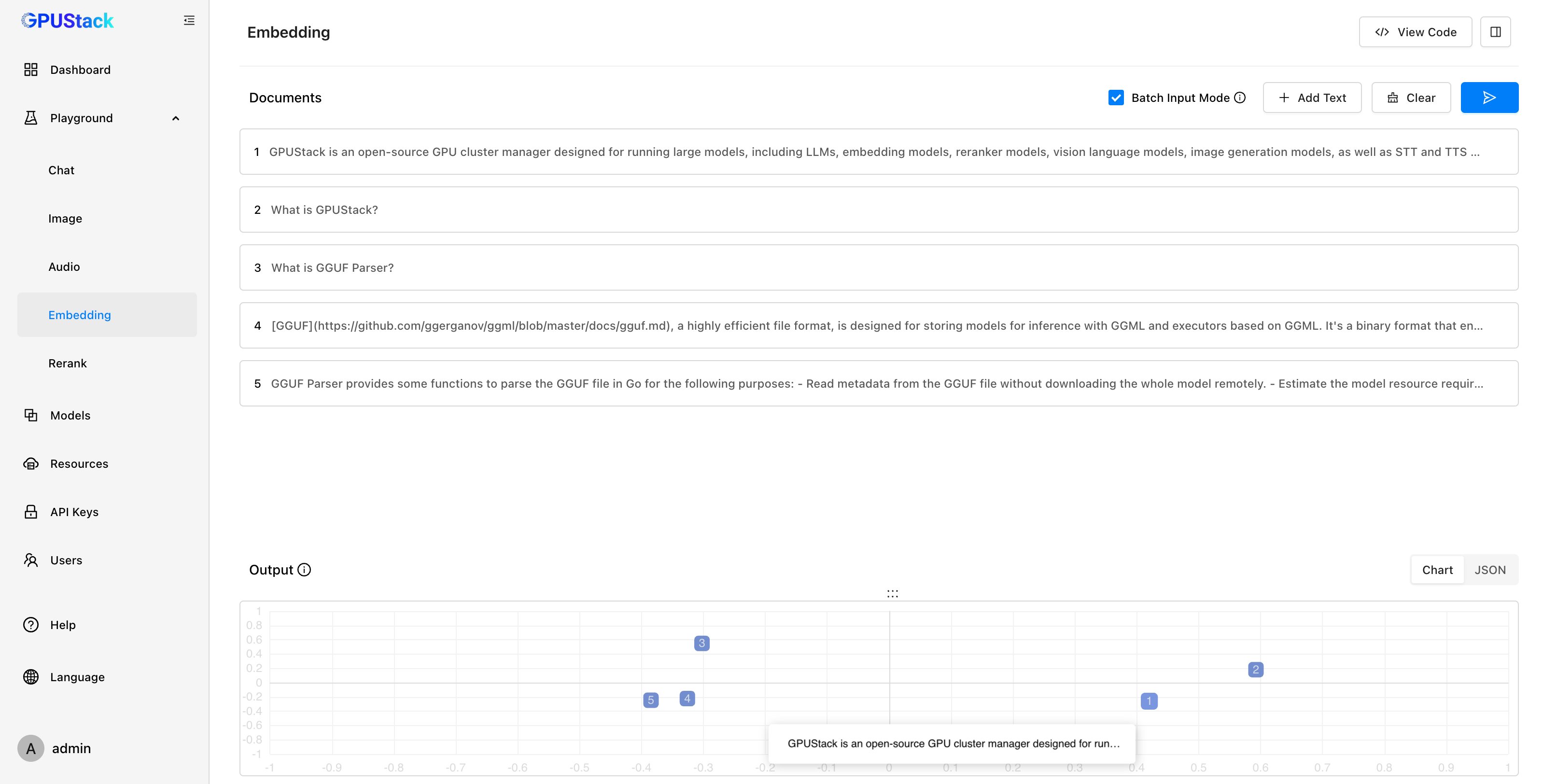
在 RAG 系统中,Embedding 模型用于将知识库中的文本转化为向量,存储到向量数据库。当用户提问时,问题同样会经过 Embedding 模型的向量化处理,通过计算向量距离在向量数据库中检索出最相关的上下文,并将其与用户问题一起传递给大模型。GPUStack 支持在 Linux、Windows 和 macOS 平台的各种 GPU/NPU 上部署 Embedding 模型。
Playground 还可以对 Embedding 模型进行调测,提供直观的可视化分析。通过对嵌入向量进行 PCA(主成分分析)降维,用户能够在降维坐标空间中对比多段文本的距离,直观判断向量距离和文本相似度。
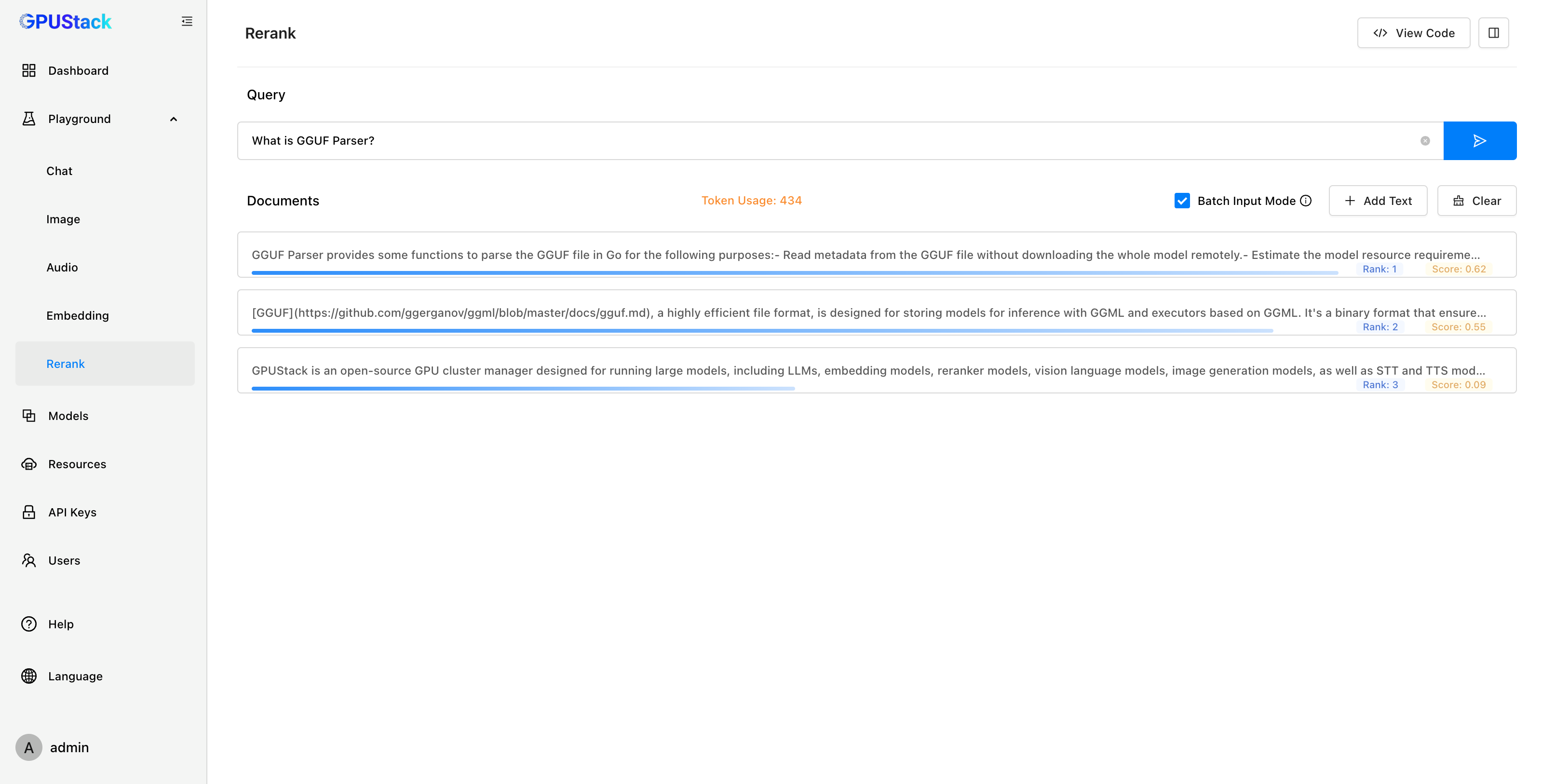
- Rerank 重排模型
在 RAG 系统中,Rerank 模型用于对向量检索召回的多个上下文进行重排序,确保将最相关的上下文传递给大模型,从而提高回答的准确性。GPUStack 支持在 Linux、Windows 和 macOS 平台的各种 GPU/NPU 上部署 Rerank 模型。
Playground 还可以对 Rerank 模型进行调测,提供直观的重排结果展示。用户可以输入 Query 和一组 Documents,模型会根据 Query 的内容对 Documents 进行排序,并返回每个文档的相关性得分。用户可以通过结果判断模型对输入的理解和排序的准确性。
- 文生图模型
GPUStack 可以开箱即用地部署 Stable Diffusion 和 FLUX 等文生图模型,支持在 NVIDIA、Apple Metal、华为昇腾和摩尔线程等各种 GPU / NPU 上运行文生图模型。并提供了 Playground 试验场供开发者调测图像生成的效果,从而试验不同模型的最佳实践参数配置。

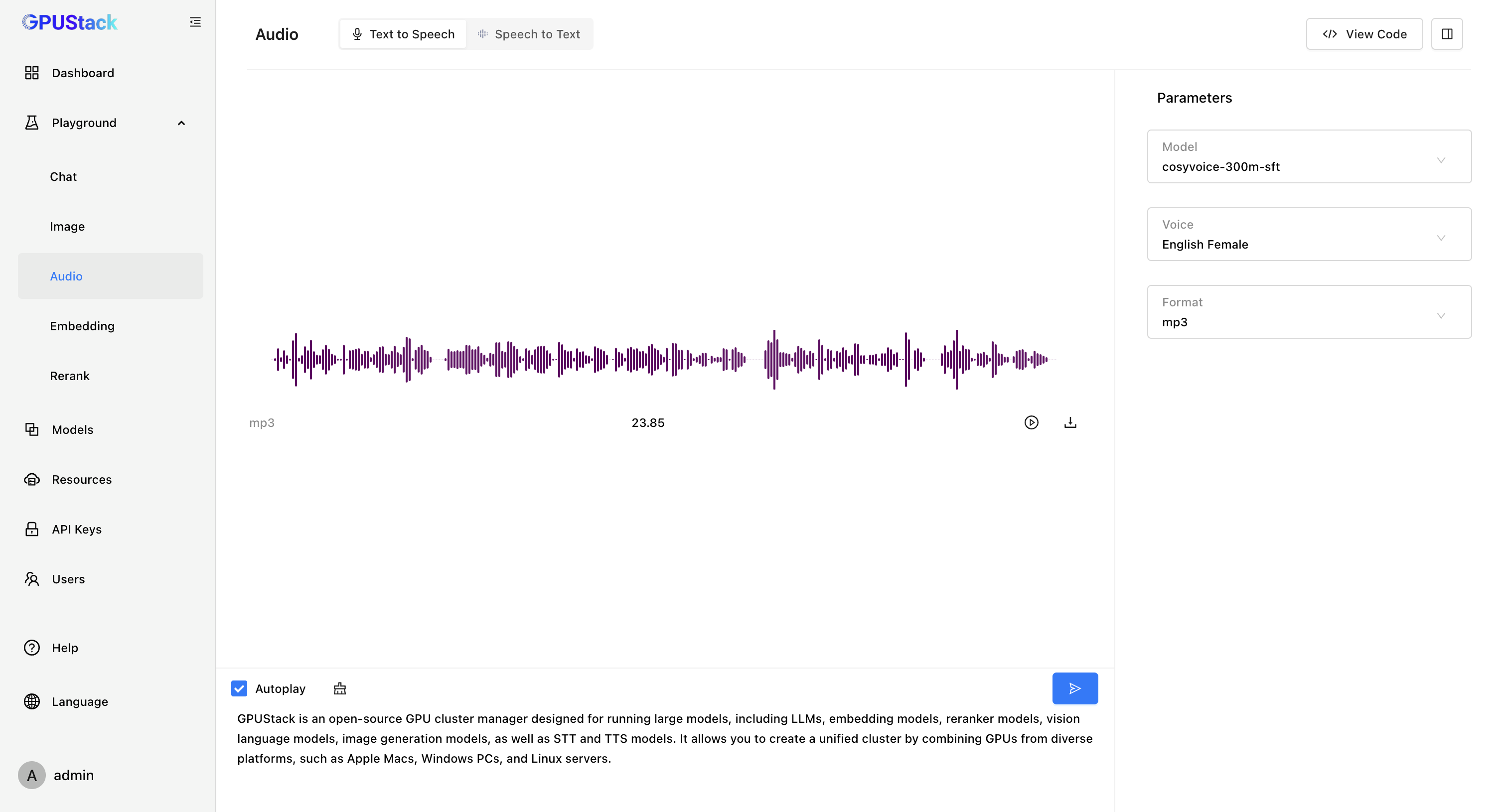
- Text-to-Speech(TTS)文本转语音模型
GPUStack 可以在 NVIDIA GPU 或 CPU 上部署 Text-to-Speech(TTS)文本转语音模型,并提供了 Playground 试验场供开发者调测文本转语音的效果。
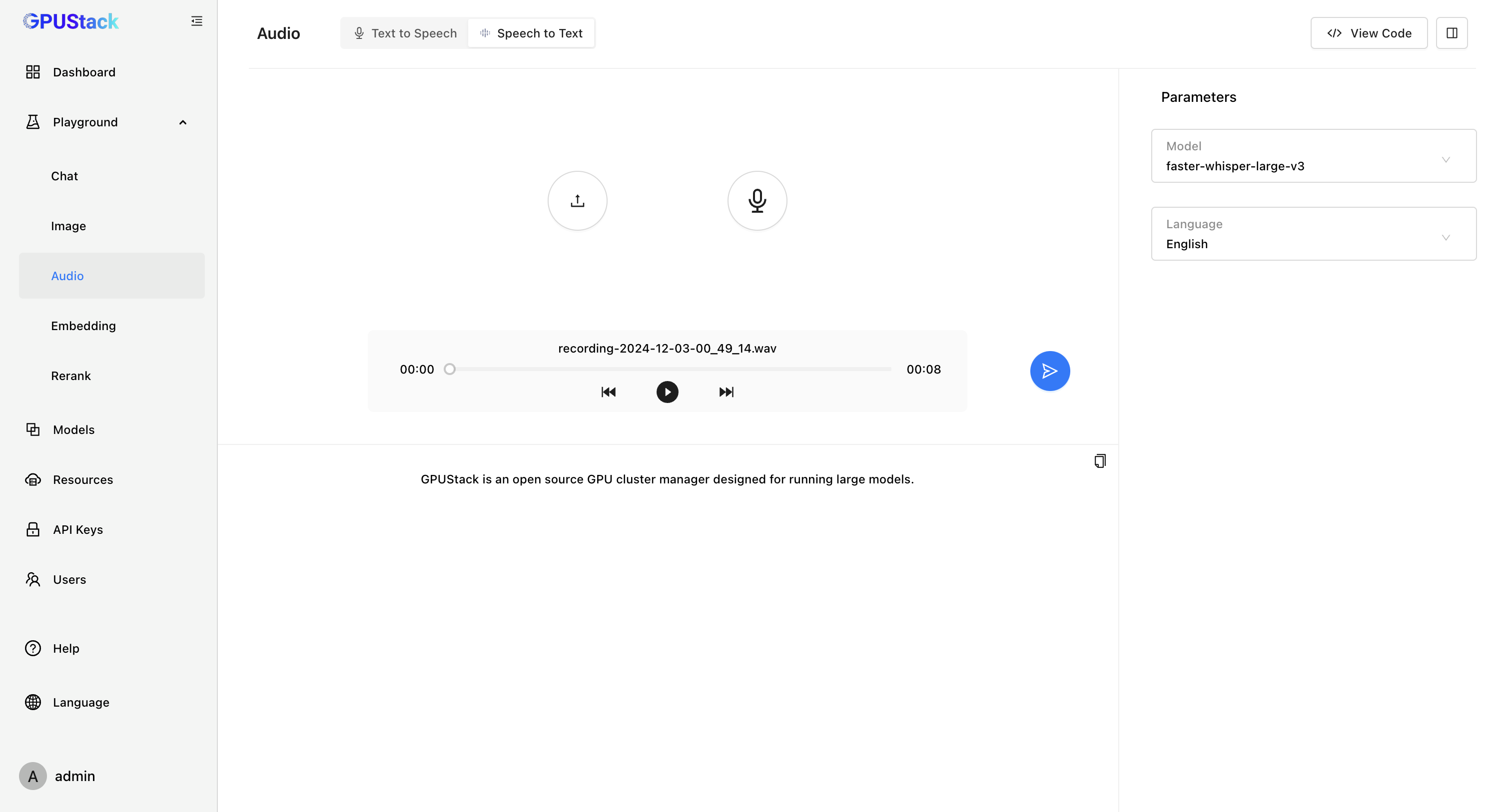
- Speech-to-Text(STT)语音转文本模型
GPUStack 可以在 NVIDIA GPU 或 CPU 上部署 Speech-to-Text(STT)语音转文本模型,并提供了 Playground 试验场供开发者调测语音转文本的效果。
- 集成对接能力
GPUStack 提供标准的 OpenAI 兼容 API,支持 LangChain、LlamaIndex、GraphRAG、Dify、FastGPT、RAGFlow、Open WebUI 等各种 LLM 应用框架、RAG 应用和 AI Agent 应用的对接。企业不仅可以快速将现有的大模型应用无缝迁移到 GPUStack 部署的私有模型服务,还能根据不同场景和需求,统一认证对接各种模型,灵活构建定制化的 RAG 系统和 AI Agent 应用。
- 企业级管理能力
GPUStack 是面向企业级的大模型部署解决方案,提供国产化支持、就地升级、推理引擎版本管理、模型升级、负载均衡高可用、用户管理、API 认证授权、GPU 和 LLM 观测指标、Dashboard 仪表板、离线部署等各种运维管理能力,帮助运维人员轻松应对异构适配、模型迭代、权限控制、运维观测等管理需求,降低了大模型部署和管理的复杂度。
安装 GPUStack
需要 Python 3.10 ~ Python 3.12
在 Linux 或 macOS 上通过以下命令安装(使用国内源加速):
curl -sfL https://get.gpustack.ai | INSTALL_INDEX_URL=https://pypi.tuna.tsinghua.edu.cn/simple sh -s - --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
在 Windows 上以管理员身份运行 Powershell,通过以下命令安装(使用国内源加速):
$env:INSTALL_INDEX_URL = "https://pypi.tuna.tsinghua.edu.cn/simple"
Invoke-Expression "& { $((Invoke-WebRequest -Uri 'https://get.gpustack.ai' -UseBasicParsing).Content) } -- --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
当看到以下输出时,说明已经成功部署并启动了 GPUStack:
[INFO] GPUStack service is running.
[INFO] Install complete.
GPUStack UI is available at http://localhost.
Default username is 'admin'.
To get the default password, run 'cat /var/lib/gpustack/initial_admin_password'.
CLI "gpustack" is available from the command line. (You may need to open a new terminal or re-login for the PATH changes to take effect.)
按照脚本的输出指引,拿到登录 GPUStack 的初始密码。
在 Linux 或 macOS 上执行:
cat /var/lib/gpustack/initial_admin_password
在 Windows 上执行:
Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustack\initial_admin_password") -Raw
在浏览器访问 GPUStack UI,用户名 admin,密码为上面获得的初始密码。
重新设置密码后,进入 GPUStack:
纳管 GPU 资源
GPUStack 可以纳管 Linux、Windows 和 macOS 设备的 GPU 资源,通过以下步骤来纳管这些 GPU 资源。
其他节点需要通过认证 Token 加入 GPUStack 集群,在 GPUStack Server 节点执行以下命令获取 Token:
在 Linux 或 macOS 上:
cat /var/lib/gpustack/token
在 Windows 上:
Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustack\token") -Raw
拿到 Token 后,在其他节点上运行以下命令添加 Worker 到 GPUStack,纳管这些节点的 GPU(将其中的 http://YOUR_IP_ADDRESS 替换为你的 GPUStack 访问地址,将 YOUR_TOKEN 替换为用于添加 Worker 的认证 Token):
在 Linux 或 macOS 上:
curl -sfL https://get.gpustack.ai | INSTALL_INDEX_URL=https://pypi.tuna.tsinghua.edu.cn/simple sh -s - --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url "https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com"
在 Windows 上:
$env:INSTALL_INDEX_URL = "https://pypi.tuna.tsinghua.edu.cn/simple"
Invoke-Expression "& { $((Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content) } -- --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN --tools-download-base-url 'https://gpustack-1303613262.cos.ap-guangzhou.myqcloud.com'"
通过以上操作步骤,我们创建了一个 GPUStack 环境并纳管了多个 GPU 节点,后面就可以使用 GPUStack 来体验上面提及的各种功能了。
写在最后
上手体验了 GPUStack 之后,我发现 GPUStack 真的是一个低门槛、易上手、开箱即用的大模型服务平台,各项功能简单易用,可以帮助企业快速整合和利用各种异构 GPU 资源,在短时间内快速搭建起一个企业级的私有大模型服务平台。
GPUStack 团队也是拥有全球顶级开源项目经验的研发团队,项目的各种功能设计和文档的完整性都相当不错,团队从一开始就面向全球用户,目前的开源用户遍布海内外,团队一直致力于将国产开源项目推广到全世界。期待 GPUStack 团队能够越做越好,取得更大的成功。
看到这里咱必须去 GitHub 给 GPUStack 送上 Star 的祝福!
GitHub 仓库:https://github.com/gpustack/gpustack
阳明和他朋友们的一些项目





Kubernetes 进阶训练营
通过大量的实战案例,帮助你打通 Kubernetes 的任督二脉,从零到一系统掌握 Kubernetes 的核心技术。课程涵盖云原生存储、服务网格、GitOps、可观测性等热门技术,让你快速成为云原生技术专家。
了解详情微信公众号
扫描下面的二维码关注我们的微信公众帐号,在微信公众帐号中回复◉加群◉即可加入到我们的 kubernetes 讨论群里面共同学习。
