
上节课我们完成了最基本的流水线流程,接下来的工作就是来实现之前的具体 Pipeline 脚本了。
阳明的博客
大家好,我叫阳明,前小米高级开发工程师,现在回到家乡成都,独立开发者一枚,一个有着产品思维的工程师,现在也在努力将自己的产品思维体系化,全栈工程师,现阶段专注 Kubernetes 和 AIGC,创建了「k8s技术圈」社区、「优点知识」知识付费网站以及「快课星球」AI全栈开发学习网站。我可以提供企业容器化方面的知识培训和咨询工作,感兴趣的可以通过微信 gitops 和我联系。
阳明和他朋友们的一些项目




Helm Chart 模板开发技巧
Helm Chart 在我们使用的时候非常方便的,但是对于开发人员来说 Helm Chart 模板就并不一定显得那么友好了,本文主要介绍了 Helm Chart 模板开发人员在构建生产级的 Chart 包时的一些技巧和窍门。
Kubernetes 进阶训练营

Kubernetes 网络故障常见排查方法
 网络可以说是 Kubernetes 部署和使用过程中最容易出问题的了,最主要的是对网络技术非常熟悉的人员相对较少,和 Kubernetes 结合后能搞透彻网络这块的就更加稀少了,导致我们在部署使用过程中经常遇到一些网络问题。本文将重点关注网络,列出我们遇到的一些问题,包括解决和发现问题的简单方法,并就如何避免这些故障提供一些建议。
网络可以说是 Kubernetes 部署和使用过程中最容易出问题的了,最主要的是对网络技术非常熟悉的人员相对较少,和 Kubernetes 结合后能搞透彻网络这块的就更加稀少了,导致我们在部署使用过程中经常遇到一些网络问题。本文将重点关注网络,列出我们遇到的一些问题,包括解决和发现问题的简单方法,并就如何避免这些故障提供一些建议。
微博图床一键迁移到阿里云 OSS
今天发现博客上大量图片显示不出来了,打开Chrome控制台一看出现了大量的 403 图片
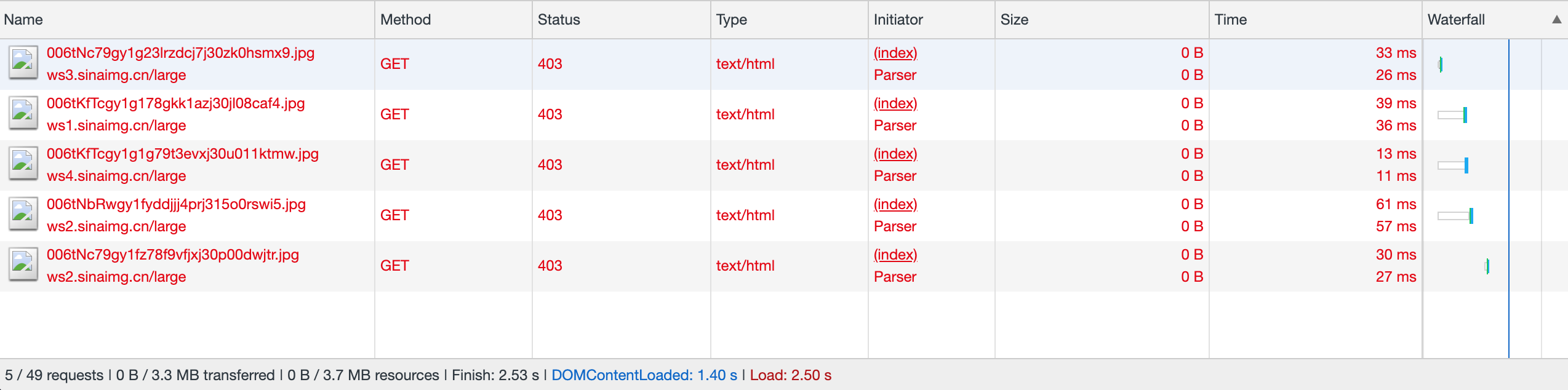
这就是薅微博图床的羊毛的后果,应该是微博图床这边升级了访问策略,幸运的是直接打开图片地址还是可以访问的,不然就有得 ಥ_ಥ 了,这么多图片丢失了那就坑爹了,怎么办?迁移呗~~
如何在 Keynote 中插入高亮代码?
这两天在开始做 Golang 的实战课程,课程内容基本上规划得差不多了,现在在开始做 PPT 内容,但是做出的 PPT 内容始终感觉有点丑陋,特别是有时候需要或多或少的在 PPT 中展示下代码的时候,直接截图效果也不是很有好。于是一通查找在 keynote 中能够很好的显示代码的方法,找到一个比较友好的解决方法:使用 RTF 格式插入文字格式的高亮代码。
利用 Hugo Pipes 处理资源文件
Hugo是一个非常强大的静态博客生成工具,没错你们正在看的本博客也是用Hugo来生成的博客文章。作为一个对速度有着强烈要求的博主,整个网站使用的阿里云的全站加速功能,虽然博客上图片资源不算少,但是大部分用户访问的时候应该速度不算太慢,为了能够进一步提升访问速度,自然而然想到的就是对 CSS 样式或者 JS 文件进行合并压缩了。
在 Hugo 文章中添加 Adsense 广告单元

之前在首页添加了 Google Adsense 信息流广告,文章详情页没有添加,而文章详情页是 Hugo 编译 markdown 文档过后的,我们可以通过主题下面的layouts/_default/single.html看到模板中是通{{ .Content }}进行渲染的,那么如果我们想要在文章中添加 Adsense 广告的话呢?应该怎样添加呢?
其实很简单,我们只需要在文章中加上一个特殊的标签,然后在模板中将该标签替换掉即可。我们在用 Hugo 写文章的时候添加的< !--more-->标签就是这种原理。
nginx-ingress 的安装使用
nginx-ingress 和 traefik 都是比如热门的 ingress-controller,作为反向代理将外部流量导入集群内部,将 Kubernetes 内部的 Service 暴露给外部,在 Ingress 对象中通过域名匹配 Service,这样就可以直接通过域名访问到集群内部的服务了。相对于 traefik 来说,nginx-ingress 性能更加优秀,但是配置比 traefik 要稍微复杂一点,当然功能也要强大一些,支持的功能多许多,前面我们为大家介绍了 traefik 的使用,今天为大家介绍下 nginx-ingress 在 Kubernetes 中的安装使用。
如何保护对外暴露的 Kubernetes 服务
有时候我们需要在 Kubernetes 中暴露一些没有任何安全验证机制的服务,比如没有安装 xpack 的 Kibana,没有开启登录认证的 Jenkins 服务之类的,我们也想通过域名来进行访问,比较域名比较方便,更主要的是对于 Kubernetes 里面的服务,通过 Ingress 暴露一个服务太方便了,而且还可以通过 cert-manager 来自动的完成HTTPS化。所以就非常有必要对这些服务进行一些安全验证了。
基于 Jenkins、Gitlab、Harbor、Helm 和 Kubernetes 的 CI/CD(一)
上节课和大家介绍了Gitlab CI结合Kubernetes进行 CI/CD 的完整过程。这节课结合前面所学的知识点给大家介绍一个完整的示例:使用 Jenkins + Gitlab + Harbor + Helm + Kubernetes 来实现一个完整的 CI/CD 流水线作业。
其实前面的课程中我们就已经学习了 Jenkins Pipeline 与 Kubernetes 的完美结合,我们利用 Kubernetes 来动态运行 Jenkins 的 Slave 节点,可以和好的来解决传统的 Jenkins Slave 浪费大量资源的缺点。之前的示例中我们是将项目放置在 Github 仓库上的,将 Docker 镜像推送到了 Docker Hub,这节课我们来结合我们前面学习的知识点来综合运用下,使用 Jenkins、Gitlab、Harbor、Helm、Kubernetes 来实现一个完整的持续集成和持续部署的流水线作业。
《深入浅出Prometheus》
千呼万唤始出来,国内第一本全方位讲解Prometheus的书籍《深入浅出Prometheus》终于出版了,非常荣幸能和陈晓宇、陈啸两位老师参与本书的编写,这也是我参与的第一本严格意义上的书籍,另外两位老师对于Prometheus研究的深度让我非常佩服,在编写本书的过程中也学习到了很多专业的知识,特别是关于Prometheus原理和源码方面的认识,之前都只是局限于应用层面,在了解了原理过后显然可以让我们更加有信心去使用Prometheus。